INVITE sip:[email protected] SIP/2.0 Via: SIP/2.0/UDP pc33.atlanta.com;branch=z9hG4bKnashds8 To: Bob <[email protected]> From: Alice <[email protected]>;tag=1928301774 Call-ID: a84b4c76e66710 CSeq: 314159 INVITE Max-Forwards: 70 Date: Thu, 21 Feb 2002 13:02:03 GMT Contact: <sip:[email protected]> Content-Type: application/sdp Content-Length: 147 v=0 o=UserA 2890844526 2890844526 IN IP4 here.com s=Session SDP c=IN IP4 pc33.atlanta.com t=0 0 m=audio 49172 RTP/AVP 0 a=rtpmap:0 PCMU/8000
Università degli Studi di Milano
Facoltà di Scienze MM.FF.NN.
Corso di laurea triennale in Informatica
IMS e JAIN SLEE, un’architettura per lo sviluppo di servizi di telecomunicazione a valore aggiunto
Domenico Briganti <[email protected]> v1.0, June 2008
Relatore interno: Prof. Claudio Bettini
Correlatore esterno: Dott. Antonio D’Amato
Lo sviluppo dello Scheduling Resource Adaptor
Introduzione
Pochi settori si sviluppano a ritmi frenetici come quelli delle telecomunicazioni. Gli operatori di rete fissa e mobile e i Service Provider operano in un mercato molto competitivo in cui è sempre più difficile realizzare margini a fronte di investimenti che restano comunque elevati.
Il continuo aggiornamento delle tecnologie applicabili alle reti di telecomunicazioni migliora l’efficienza e le prestazioni, è il fattore fondamentale dell’aumento di produttività e redditività, consente una maggiore flessibilità di applicazione e permette una sensibile riduzione dei costi. L’innovazione in questo campo è essenziale quanto, se non più, il Time-To-Marker (TTM), cioè il tempo che trascorre dall’ideazione di un prodotto alla sua effettiva commercializzazione.
L’investire nelle nuove tecnologie per ridurre i costi e cogliere le nuove opportunità offerte dalla convergenza delle reti di comunicazione, dei contenuti e dei dispositivi multimediali risulta quasi obbligatorio.
Servizi nuovi stanno nascendo grazie alle tecnologie ora presenti. Servizi a valore aggiunto (VAS), non essenziali come la semplice chiamata, ma che generano grossi ricavi per i player del settore. Gaming on line, download di loghi e suonerie, MMS, SMS Chat, Push-to-Talk ecc. hanno garantito un volume d’affari ogni anno più evidente come è possibile vedere in Figura 1, dati provenienti dall’Osservatorio sui Mobile Context 2007 promosso dalla School of Management del Politecnico di Milano.
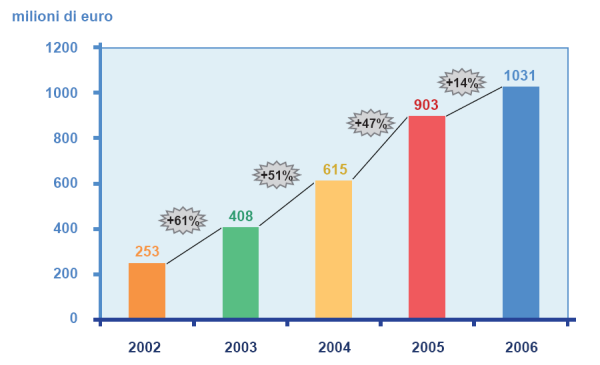
Valore del mercato dei VAS in Italia
— Osservatorio Mobile Content 2007
— Osservatorio Mobile Content 2007
Per far questo, le società di Telecomunicazione (le cosiddette TLC) hanno bisogno di sistemi che permettano lo sviluppo e la messa in opera di servizi a valore aggiunto in maniera rapida e che interagiscano con altri servizi, molti già esistenti e magari di altri operatori.
Per raggiungere questo obiettivo, i Carrier, nel corso del tempo, si sono uniti sempre più in associazioni il cui scopo è la standardizzazione delle tecnologie usate. Questo agevola l’interoperabilità tra reti di operatori diversi e accelera i tempi di sviluppo di servizi portabili da una piattaforma ad un’altra.
Il gruppo di lavoro congiunto, 3GPP, ha formalizzato una nuova architettura di rete che si basa sugli standard Internet e che si prefigge come la nuova rete per le compagnie telefoniche, indipendentemente dalle loro dimensioni. Questa architettura prende un nome di Next Generation Network (NGN) ed il sistema con cui viene realizzata prende il nome di IMS, Ip Multimedia Subsystem.
La Next Generation Networks è un’evoluzione delle vecchie (ma ancora dominanti) reti di telecomunicazioni PSTN in cui i collegamenti tra gli utenti avvenivano a “commutazione di circuito”, in pratica si instaura un circuito virtuale, simile a quello che si aveva agli esordi della telefonia con i centralini, tra le due terminazioni. Questa condizione era ottima per l’uso della rete che se ne faceva fino ad una decina d’anni fa, e cioè quello delle sole classiche telefonate, in cui c’è una continua comunicazione tra le parti solo in quel lasso di tempo. Nell’era internet una comunicazione simile non è accettabile in quanto tra due utenti o tra utente e gestore, c’è uno scambio di dati, anche di grosse dimensioni, ma non in maniera continua, e questa modalità è osservabile ad esempio nella navigazione su internet. Ed è proprio da qui che la NGN prende l’idea di una rete packet-switching.
La comunità di sviluppatori Java, riunita formalmente nell’associazione che prende il nome di Java Community Process (JCP), e più espressamente SUN hanno deciso di cogliere la sfida della realizzazione di piattaforme per il rapido sviluppo e installazione di componenti e servizi in grado di indirizzare anche le necessità della rete IMS.
Sono cosi nati diversi progetti che fanno parte di un piano di sviluppo a più ampio respiro chiamato JAIN, Java API for Intelligent/Integrated Network. JAIN raggruppa progetti che riguardano sia tecnologie di rete e protocolli, quale ad esempio JainSip, che tecniche per la creazione in modalità grafica di servizi.
È proprio qui infatti che vengono redatte le specifiche che prevedono la creazione e l’esecuzione dei servizi a valore aggiunto, che prendono il nome di Service Creation Environment (SCE) e Service Logic Execution Environment (SLEE).
Lo SLEE è un componente importante per la nuova NGN. Infatti rappresenta l’Application Server in cui risiedono le logiche dei servizi che danno “l’intelligenza” alla rete. La caratteristica di questa componente è quella di eseguire i servizi a valore aggiungo che un operatore può fornire ai propri clienti basandosi su informazioni esterne alla rete stessa. È quindi in grado di interfacciarsi a vari sistemi, come quelli di posta elettronica, presenza, fatturazione, server web, news e molti altri per poi erogare la prestazione per cui il servizio è stato realizzato.
Un componente di cui si sente la mancanza in un prodotto simile è quello che permette di poter schedulare in modo sofisticato una determinata prestazione nel tempo.
Il lavoro qui presentato vuole colmare questa mancanza sviluppando un modulo per l’Application Server JAIN SLEE che da la possibilità di fissare degli eventi nel tempo, come l’invio di SMS o la creazione di sessioni multimediali (conferenze/chiamate vocali), per la loro attivazione nell’instate di tempo indicato.
Vengono si seguito presentate tre sezioni, la prima illustra l’architettura di rete in cui i maggiori operatori stanno investendo, si tratta dell’IP Multimedia Subsystem (IMS), la futura piattaforma di rete con cui si realizzerà la NGN.
La seconda riguarda il funzionamento del nodo dell’infrastruttura che realizza l’Application Server, SLEE, e la relativa implementazione fornita da Mobicents, un prodotto open source compliant alle specifiche JAIN SLEE 1.1,
Nella terza parte vedremo come è stato realizzato lo sviluppo del modulo di SLEE che di occupa della calendarizzazione degli servizi, lo Scheduling Resource Adaptor.
Lo scenario
In questa prima parte vengono descritte le varie componenti che formano la futura infrastruttura di rete di un fornitore di servizi di telecomunicazioni. L’insieme prende il nome di IP Multimedia Subsystem (IMS), è uno standard internazionale che permetterà agli operatori di disporre di una piattaforma adatta a fornire servizi di tipo multimediale in maniera rapida con una totale conversione alle reti IP.
L’evoluzione delle tecnologie di comunicazione
Oggi “sembra” che per il telefono fisso gli anni stiano passando lentamente. È cambiato l’aspetto, più giovane, e la ruota è stata sostituita dai tasti, poco più comodi e veloci. Il sembra tra virgolette è d’obbligo, infatti se per noi utenti le differenze negli ultimi decenni sono state minime, dalla parte della centrale telefonica l’innovazione è stata importante. Infatti si è passati da centrali elettromeccaniche a quelle elettriche, evolutesi in centrali elettroniche in grado di offrire servizi come richiamata su occupato, segreteria telefonica, avviso di chiamata, e negli ultimi anni a centrali computerizzate (softswitch) in grado di far passare la nostra voce attraverso la rete intranet/internet per una maggiore efficienza, capacità e controllo.
La fonia mobile invece ha fatto passi da gigante da entrambi i punti di vista (utente e centrale). Ripercorriamo brevemente quella che è stata l’evoluzione della telefonia mobile dalla sua nascita. In base alla tecnologia radio usata, la storia del telefonino è suddivisa in generazioni:
|
0G
|
si usa per indicare tutti i sistemi di telefonia precedenti all’uso di tecniche di trasmissione dette a celle (quindi trasmissioni per-cellular). Questi telefoni erano generalmente montati sulle auto e camion per le loro dimensioni e il loro peso. Le tecniche trasmissive usate erano MTS (Mobile Telephone System), IMTS (Improved MTS) e AMTS (Advanced MTS), tutte analogiche e che impegnavano un intero canale radio per ogni comunicazione (originariamente erano 3 i canali per l’intera area metropolitana!). I primi sistemi di questo tipo risalgono, commercialmente parlando, al 1946, quando la Motorola insieme a Bell System offrirono in America il primo servizio di telefonia mobile usando il sistema MTS. |
|
1G
|
questa generazione segna la nascita dei sistemi cellulari, realizzati intorno al 1975-80. Il nome deriva infatti dalla suddivisione che si fece del territorio, a celle appunto, per inserire un maggior numero di BTS (Base Transceiver Stations, il “ripetitore” del telefonino) e sfruttare così il riuso delle frequenze per aumentare la capacità della rete. La rete è di tipo analogico, si sviluppa contemporaneamente nel mondo anche se con tecnologie diverse e non interoperabili. NMT (Nordic Mobile Telephone) è usata in Svizzera, Norvegia, Russia, mentre AMPS (Advanced Mobile Phone System) negli Stati Uniti, TACS (Total Access Communications System) nel Regno Unito, C-450 in Germania Est, Portogallo e SudAfrica, Radiocom 2000 in Francia, RTMS (Radio Telefono Mobile di Seconda Generazione) prima e il TACS (dal ‘91) poi in Italia. JTACS (Japan Total Access Communications System) in Giappone. |
|
2G
|
GSM. Questa è la rivoluzione della seconda generazione di telefonia mobile. Dopo circa 10 anni di lavori e sperimentazioni, nasce in Europa lo standard Global System for Mobile Communications, frutto della collaborazione di produttori, operatori, amministrazioni pubbliche, service provider, enti di ricerca ed utilizzatori (più di 650 membri anche extra-europei) riuniti nell’organismo indipendente ETSI (European Telecommunications Standards Institute). Il GSM è uno standard che prevede l’uso di tecniche cellulari (come la prima generazione), la modulazione di frequenza TDMA (Time Division Multiple Access) per far comunicare contemporaneamente più utenti sullo stesso canale e una trasmissione completamente digitale e cifrata delle informazioni. Questo nuovo standard permise l’interoperabilità tra reti di operatori e Stati diversi e di conseguenza la nomadicità dell’utente dove era presente un operatore GSM (roaming nazionale/internazionale). Un’estensione alla rete GSM si ebbe con l’introduzione, nel 2001, del GPRS (General Packet Radio Service) che supporta la trasmissione dati a pacchetto su reti GSM. Detto anche 2.5G, il GPRS rappresenta l’anello che lega le reti 2G a commutazione di circuito con le future 3G, a commutazione di pacchetto (reti simili ad internet piuttosto che alla telefonia tradizionale). Una successiva evoluzione del GPRS si ha con l’introduzione dell’EDGE (Enhanced Data rates for GSM Evolution), datata 2003, detto non ufficialmente 2.75G, che aumenta la velocità di connessione reale dai 50-60 kb/s a 150-200 kb/s. |
|
3G
|
in altre parole, l’UMTS (Universal Mobile Telecommunication System). È lo standard del 3GPP per implementare servizi innovativi e multimediali wireless, realizzando la convergenza tra internet e comunicazione mobile (vedi Cap2: 3GPP). Realizzato dopo un studio durato anni, e ancora in evoluzione, l’UMTS è la risposta ai bisogni di alta velocità degli utenti utilizzatori di tecnologie multimediali. Videochiamate (considerata dagli analisti la killer-application del 3G, rivelatasi poi una previsione errata), VoIP, MMS, scambio di immagini, navigazione al alta velocità su internet, sono solo alcuni delle nuove opportunità che realizza il 3G. Le velocità promesse sono paragonabili alle prime ADSL, vanno dai 144 kbit/s ad oltre 3 Mbit/s dipendentemente dalla distanza dalla BTS e dalla velocità con cui si sposta il terminale mobile. Nonostante la partecipazione al progetto dei maggiori player a livello mondiale, e il loro sforzo a uniformare le tecnologie, non si è riusciti ad ottenere un unico standard per l’accesso al canale wireless (per diverse ragioni, anche politiche). Così abbiamo 3 grandi aree: WCDMA in Europa, CDMA2000 in America e il TD-SCDMA in Cina (quest’ultimo creato appositamente per scopi politico-economici). Anche qui, come per il 2G, ci sono delle evoluzioni intra-generazione: Sotto il nome di HSPA (High-Speed Racket Access) vengono raggruppate due protocolli che migliorano la codifica con cui i dati sono trasmessi e usano una differente modulazione del segnate: 3.5G, rappresenta la tecnologia HSDPA (High-Speed Downlink Packet Access) in grado di ricevere dati fino a 14,4 Mb/s e di trasmetterli fino a 384 kb/s (velocità teoriche, sappiamo che la realtà è ben diversa, si calcola che con l’aumentare dei dispositivi HSDPA la velocità possa scendere fino ad oscillare tra 0,5 e 1,5 Mb/s). Mentre il 3.75G è l’HSUPA (High Speed Uplink Packet Access), tecnologia che mira ad aumentare la velocità in uplink, che, in teoria, può raggiungere i 5 Mb/s. |
I fattori stimolanti di una nuova piattaforma
Negli ultimi vent’anni abbiamo visto evolvere il telefono, sia fisso che mobile, in una maniera esponenziale. Dalle semplici telefonate offerte agli utenti, si è passati a servizi sempre più evoluti quali le videochiamate i file sharing, instant messaging, servizi che fino a pochi anni fa erano solo ad appannaggio del web. La crescita è stata rapida e ha portato con se un’innovazione continua delle tecnologie che stanno alla base dei due mondi – fisso e mobile. Oggi siamo di fronte ad un nuovo traguardo, quello che da tempo, almeno gli addetti ai lavori, chiamano “convergenza fisso - mobile”. Una nuova era in cui, come un famoso spot pubblicitario ci fa notare, la rete, le comunicazioni, le informazioni sono tutte intorno a noi, dove non abbiamo nessuna barriera d’accesso, ma da qualunque posto e da qualunque dispositivo, possiamo accedere ai dati che ci necessitano.
La convergenza fisso mobile
Oggi si parla tanto di convergenza fisso - mobile (FMC). Essa rappresenta l’integrazione dei sistemi wireless e wireline per creare un singolo network di comunicazione e servizi. Un esempio tipico di FMC è la possibilità di avere un unico numero sia per il cellulare che per il fisso, quindi un unico terminale che è in grado di allacciarsi alla rete WiFi quando disponibile (per fare le cosiddette VoIP calls, chiamate dalla rete internet a costo nullo o molto basso), o alla rete GSM/GPRS/UMTS dell’operatore fuori del raggio d’azione della rete casalinga, passando da una rete all’altra senza interrompere la comunicazione.
Il ruolo dei Media
Una rete che permette la fruizione di video, inteso sia come chiamata video che come IPTv o videosharing come i grandi portali YouTube, TuoVideo ecc., la navigazione veloce in internet (quella vera, non col WAP…) e quindi l’accesso a grandi e popolari siti come MySpace, MSN, Yahoo non fa altro che aumentare l’interesse delle media company che guardano a queste tecnologie come il punto d’incontro con l’utente finale. La possibilità che hanno gli utenti si caricare e scaricare i contenuti, ancorché autoprodotti, è un vero punto di forza e lo si è visto anche dal crescente successo del Web 2.0 e dai servizi di collaborazione usati sia nel tempo libero che come strumenti per migliorare la produttività lavorativa.
Anche la pubblicità gioca un ruolo fondamentale nei nuovi sistemi. Oggi quella di internet diventa paragonabile, in termini di volume d’affari, a quella di giornali, riviste e radio, e la possibilità di conquistare un cosi vasto pubblico attraverso il nuovo Mobile Web 2.0 fa gola a molti.
I nuovi servizi
Oltre alle media company, l’interesse a nuove e più performanti reti di comunicazione si fa sentire anche da software house che potranno sviluppare soluzioni innovative anche a problemi già affrontati, incrementando il proprio bacino d’utenza. Un esempio, molto concreto e che ha avuto un grosso boom negli ultimi anni, è la navigazione satellitare. Grazie alla rilevazione della posizione tramite GPS o triangolazione del punto dai dati provenienti dalle antenne GSM, ed alla connessione ad internet, il sistema sarà in grado di fornirci informazioni dettagliate sul traffico e consigliarci il percorso più rapito tenendo in considerazioni fattori come ingorghi, velocità di percorrenza sulla determinata strada e rallentamenti.
Un altro esempio molto interessante di applicazioni creabili con la nuova piattaforma è sempre relativo alla pubblicità, e più precisamente, si avrà la possibilità di renderla sensibile alla posizione geografica di chi la “usufruirà”. Se da una parte questa forma di comunicazione è vista negativa e superflua soprattutto se non riguarda i propri interessi, dall’altro, se il messaggio viene selezionato in base alle proprie ricerche e interessi, e viene fornito ad inserzionisti che non si trovano più lontano di un paio di isolati dall’attuale posizione, può essere molto utile e adeguato non solo per l’inserzionista ma anche per chi la pubblicità la riceve.
Gli organi di standardizzazione
Diverse entità si sono occupate, e continuano ad occuparsi, della creazione delle specifiche tecniche e non su cui si basano i recenti sistemi di telecomunicazioni. Diamo un accenno alle più importanti.
Third Generation Partnership Project – 3GPP
Fu fondato nel 1998, è un progetto a cui fanno parte gli enti e consorzi che si occupano di standardizzare i sistemi di telecomunicazioni nelle diverse parti del mondo, autorità governative e regolatorie, operatori del mercato IT, ne fanno parta ad esempio ARIB, CCSA, ETSI, ATIS, TTA e TTC (alcune di queste descritte sotto). Lo scopo originale del 3GPP era di produrre le specifiche riguardanti la terza generazione di telefonia mobile, evoluzione del GSM, sia per la core network che per la parte d’accesso radio, sviluppando l’UTRA (Universal Terrestrial Radio Access). Gli su comunque assegnato anche il compito di sviluppare e mantenere le specifiche tecniche per il Global System for Mobile communication (GSM) nella loro evoluzione del GPRS e dell’EDGE.
Internet Engineering Task Force – IETS
È l’organismo che si occupa di definire gli standard di internet e la loro evoluzione. È aperto a chiunque sia interessato o voglia dare un contributo, il lavoro viene maggiormente svolto sulle mail list dei gruppi di lavoro che di occupano delle relative tematiche con degli incontri fissati a cadenza quadrimestrali.
La collaborazione con il 3GPP è definita nell’RFC3113. Qui si elencano le ragioni della collaborazione (il 3GPP userà gli standard dell’IETF mentre quest’ultimo potrà contare sulle capacita e sulle conoscenze che il 3GPP ha sulle reti wireless), la modalità di condivisione dei documenti, le comunicazioni e i partecipanti.
Il 3GPP ha adottato molti dei protocolli dell’IETF come l’IPv6, il Domain Name System (DNS), Session Initiation Protocol (SIP), Common Open Policy Service (COPS), Resource ReSerVation Protocol (RSVP), Session Description Protocol (SDP), Diameter (un protocollo per l’autenticazione, autorizzazione e la tassazione), Real-Time Protocol (RTP).
International Telecommunication Union –Telecommunication – ITU-T
È il settore relativo alle telecomunicazioni telefoniche e telegrafiche dell’Unione Internazionale delle Telecomunicazioni. Fornisce degli standard (o raccomandazioni) riconosciute a livello internazionale che regolamentano il settore TLC appunto.
European Telecommunications Standards Institute – ETSI
Fornisce standard a livello globale per l’ICT riguardanti telefonia fissa e mobile, convergenza, trasmissioni broadcast e tecnologie internet. È riconosciuto dalla Commissione Europea come L’Organizzazione Europea per la Standardizzazione. L’ETSI è una no profit formata dal almeno 700 membri di 60 nazioni.
Third Generation Partnership Project 2 – 3GPP2
É un progetto che si sviluppa sopra il 3GPP e che ingloba al suo interno l’IMS, qui chiamato Multi-Media Domain (MMD). Ci sono molte similitudini ma anche alcune differenze chiave come i codec usati, qui viene usato il Enhanced Variable Rate Codec (EVRC) al posto del Adaptive Multi-Rate (AMR). Altre riguardano la tassazione, le regole di controllo e servizi legacy.
Open Mobile Alliance – OMA
Formata nel giugno del 2002, l’Open Mobile Alliance mira alla standardizzazione dei servizi sui terminali mobili, il primo ad essere pubblicato è stato il Push-To-Talk over Cellular (PoC). L’OMA, impegnandosi in lavori come questo, permette a diversi fornitori di servizi di collaborare sulle funzioni chiave che il servizio stesso supporta, come la gestione delle sessioni, il QoS e la sicurezza, in modo da rendere i servizi interoperabili tra diversi fornitori.
IP Multimedia Subsystem
IP Multimedia Subsystem è un insieme di specifiche che descrivono la futura architettura per le reti di telecomunicazioni costruita sugli standard internet (IP) ed in grado di offrire servizi multimediali aggiuntivi rispetto alla sola fonia.
È un modello che vede ridurre il gap tra internet e i telefoni, grazie alla rete (fissa e cellulare) potremo infatti condividere con altre persone musica e video, giocare in real-time con altri player remoti, avere informazioni sul traffico riguardanti il nostro percorso, conferenze, chat, presenza e tanti altri servizi innovativi. L’uso di dispositivi con display ad alta definizione, potenti processori, always-on e always-connected ridefiniscono il concetto stesso di applicazioni per mobile devices.
Sicuramente non si tratta di uno scenario semplice, e tutte le sigle che indicano protocolli, server, funzionalità, interfacce non aiutano di certo. Cercheremo comunque di dare un minimo di consapevolezza su come funziona una rete IMS descrivendo leggermente gli elementi da cui è composta e le iterazioni esistenti tra di essi.
Alla fine faremo un paio di esempi relativi alla registrazione di un utente al sistema (la registrazione si ha al momento dell’accensione del telefono) e di una semplice chiamata telefonica (chiamata base in gergo tecnico).
Panoramica di IMS
L’IMS si può vedere come una piattaforma stratificata orizzontalmente, composta da tre layer (vedi Figura 7), ognuno con responsabilità differenti. Non esiste più il concetto, come nelle reti tradizionali, che un unico sistema si occupi dell’intera catena esistente tra l’invocazione del servizio e il suo termine, ma grazie a questa stratificazione (orizzontale appunto) servizi diversi possono condividere gran parte dei loro elementi, permettendo un’elevata ricusabilità di soluzioni, facilità di integrazione dei servizi esistenti, riduzione dei tempi e dei costi di sviluppo (Figura 3).
Cosi stratificato e grazie all’adozione di reti full-IP, l’IMS garantisce la completa indipendenza dalla tecnologia di accesso e la possibilità di offrire tutti i servizi innovativi che una volta appartenevano al solo mondo di internet.
Anche la mobilità dell’utente ha la sua importanza, infatti IMS (Release 8) definisce i protocolli necessari per effettuare il cosiddetto handover sia tra reti omogenee che eterogenee. Ad esempi, il dispositivo mobile, durante una chiamata standard GSM, potrebbe accorgersi di avere a disposizione una WLAN a cui connettersi, ed effettuare un handover su questa, risparmiando sulla tariffazione dato che normalmente la connessione WLAN è molto più economica rispetto a quella GSM.
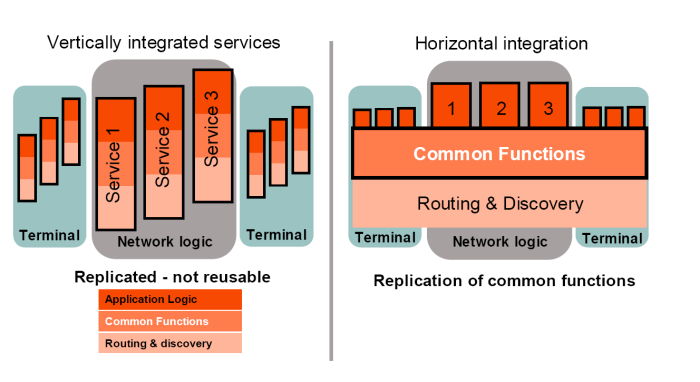
Dall’implementazione di servizi verticali all’implementazione di servizi orizzontali con
funzionalità comuni (IMS)
— Ericsson
— Ericsson
L’evoluzione di IMS
Le origini dell’IMS hanno inizio nello stesso istante in cui fu fondato il 3GPP, nel dicembre 1998 a Copenaghen (Danimarca). Fino ad allora gli standard che vennero realizzati per la telefonia mobile e fissa erano firmati dall’ETSI (che definì anche lo standard GSM e GPRS), ma si sentiva la necessità di standardizzare a livello mondiale le nuove generazioni di reti wireless (in quegli anni era aperta la discussione sulla Terza Generazione).
Le prime specifiche per le reti wireless 3G prime nascono nel 1999 prendendo il nome di Release 99 [3GPP R99].
La Release 99 è stata sviluppata in meno di un anno di lavoro grazie alla divisione dei compiti tra il 3GPP e l’ETSI. Il primo ha sviluppato i servizi, l’architettura, le codifiche WCDMA e TD-CDMA, UTRAN (UMTS Terrestrial Radio Access Network) e la parte di core network in comune con le reti esistenti, il secondo sviluppò il GSM/Enhanced Data Rates for Global Evolution (EDGE) e il relativo accesso GERAN (GSM Edge Radio Access Network). Queste specifiche consolidano le specifiche del GSM nella modalità a commutazione di pacchetto e preparano la rete a sostenere il notevole traffico di dati generato dalla futura architettura IP.
La Release 4 è stata rilasciata nel 2000. Il nome originare era Release 2000, che includeva la tecnologia All-IP, poi chiamata IMS, ma l’eccessivo lavoro rese necessario la divisione della release in Release 4 e Release 5. Anche per questo, i contenuti della Release 4 sono significamente diretti a ottimizzare e migliorare quelli della release precedente (UTRAN), ma non mancano le novità: il concetto di MSC Server-MGW, il protocollo IP nella core network, LCS (Location Services) per l’UTRAN.
La Release 5 introduce l’IMS, standard per l’accesso indipendente basato su IP e dialogante con le reti esistenti di voce a data per le connessioni fisse e mobili. L’architettura IMS rende possibile l’instaurazioni di connessioni peer-to-peer IP con tutti i tipi di client e oltre a gestire le sessioni IP, ha tutto il necessario per la completa fornitura di servizi (registrazione, sicurezza, fatturazione, roaming, controllo degli accessi, ecc.). Tutto questo forma il cuore della nuova architettura core full-IP. Fa parte di queste specifiche anche l’High Speed Downlink Packet Access (HSDPA).
La Release 6 similmente alla release 4, è un consolidamento di ciò che è stato fatto nella 5, con delle aggiunte importanti: l’accesso attraverso WLAN, l’implementazione del Qualità of Service, l’introduzione del concetto di Presenza dell’utente (informazioni aggiornate in real-time sullo stato della persona chiamata) e l’introduzione dei servizi punti-multipunto ottimizzati per il trasporto di contenuti multimediali, sia in modalità broadcast sia in modalità multicast (Multimedia Broadcast/Multicast Service, MBMS). Si sono avuti anche miglioramenti ai servizi: Location Services, Multimedia Messaging, QoS, codec audio e HDUPA (High Speed Uplink Packet Access).
La Release 7 aggiunge il supporto per all’elemento TISPAN (Telecoms & Internet converged Services & Protocols for Advanced Networks) che abilita gli utenti di rete fissa ai servizi multimediali della rete IMS, e quindi alla vera convergenza. Migliora l’High Speed Packet Access con l’introduzione del HDPA+ (HDPA Evolved) che raddoppia la capacità dei dati rispetto alla Release 5 e 6. Il Location Services per la WLAN, SMS/MMS su protocollo IP, Multimedia Telephony (MMTel), Voice Call Continuità (VCC) tra VoIP IMS e la rete a commutazione di circuito, ISM Emergency Calls, End to end QoS, Parlay X WS sono tra le nuove features della release. Degna di nota è la nuova interfaccia ICSI/IARI (IMS Communication Service ID / IMS Application Reference ID) che permette l’accesso alla core network da parte di applicazioni custom esterne alla rete dell’operatore.

UMTS Evolution
— gsmworld.com
— gsmworld.com
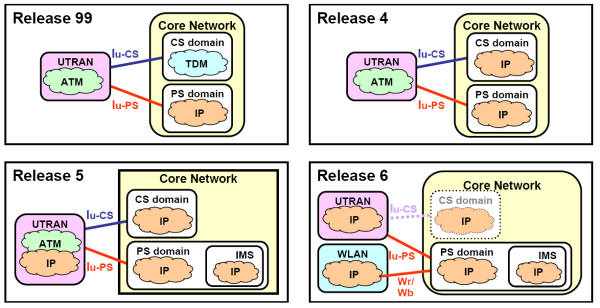
Release dell'IMS
— Politecnico di Madrid
— Politecnico di Madrid
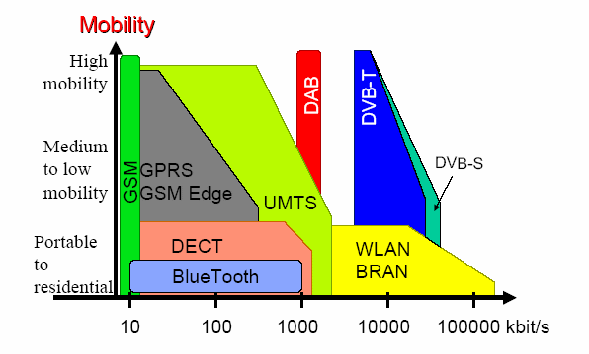
Tecnologie Wireless in rapporto con la mobilità
— Wind Telecomunicazioni
— Wind Telecomunicazioni
Uno sguardo al futuro
Il mondo corre verso il 4G mobile, che vedrà la luce (nelle prime forme) nel 2009, ma già dal 2008 ne saranno poste le fondamenta. Quest’anno sarà un succedersi delle prime aste per le frequenze ideali alla nuova generazione di servizi (2,3-2,6 GHz) e vedrà l’arrivo di prodotti per il WiMax nomadico o mobile. Il 4G porterà al culmine la guerra degli standard e forse vi porrà fine.
Due le tecnologie pronte a sfidarsi: WiMax mobile (802.16e) e Lte (Long Term Evolution).
Anche se sono frutto di due diversi organismi di standardizzazione, da fine 2007 sono stati messi nella stessa famiglia dell’IMT, la IMT-2000 che rappresentano un set di raccomandazioni dell’ITU per le reti d’accesso 3G . Significa che gli operatori e i produttori di apparati potranno sviluppare entrambe le tecnologie sulle stesse frequenze. In comune hanno buona parte dell’infrastruttura di rete: la tecnologia radio OFDMA (Orthogonal Frequency Division Multiple Access, aumenta la capacità del canale radio grazie alla migliore tolleranza alle interferenze e al multipath), il fatto di essere full-IP, l’uso di tecnologie innovative per le antenne come Mimo (Multiple Input Multiple Output) e la codifica QAM 64.
Il tutto porta a un salto avanti delle prestazioni di picco e reali rispetto al 3G. La velocità teorica con il 4G è fino a 100 Mbps in mobilità; 1 Gbps da postazione fissa.
Tra WiMax mobile ed Lte ci sono alcune piccole differenze nell’interfaccia radio;
Lte permette inoltre una maggiore mobilità, mentre WiMax mobile accetta connessioni da apparati che si spostano fino a circa 100 km/orari. Lte supporta anche la tecnica FDD (Frequency division demultiplexing), più efficiente della TDD (Time division demultiplexing), la sola supportata ad oggi dal WiMax mobile. Inoltre Lte è la diretta evoluzione dell’Umts, quindi gode di migliori potenzialità per gli studi già affrontati dalla generazione precedente e per le economie di scala . Di contro, Lte è in ritardo di circa un anno rispetto al WiMax mobile, almeno sulla roadmap commerciale.
Un altro standard 4G è l’Ultra mobile broadband, l’evoluzione del Cdma2000, ma lo scarso appoggio dal mondo TLC e la sola applicabilità all’America fanno alzare la probabilità di un abbandono.
È possibile invece che con il 4G, attraverso Lte e WiMax Mobile, Europa e Nord America useranno gli stessi standard, mentre finora le reti mobili sono state divise tra Cdma/Cdma 2000 americano e Gsm/Umts europeo.
I principali produttori hanno presentato (e mostrato in azione) al Mobile World Congress 2008 di Barcellona apparati Lte, prevedendo i lanci al pubblico nel 2010.
Ma oltre ai prodotti e alle reti, servono le frequenze (quelle sui 3,4-3,6 GHz, già assegnate in Europa, sono troppo elevate per assicurare connessioni in mobilità).
Molti operatori quindi si stanno preparando per accaparrarsi frequenze più basse, come sta succedendo in USA dove si sta avviando l’asta per i 700 MHz a cui partecipano, oltre ai grandi operatori, anche potenti net company come Google e Verizon. Mentre in Giappone, con l’asta già finita, i primi servizi a usare queste frequenze sono previsti per il 2009.
Le licenze potranno essere usate non solo con il WiMax ma anche con tecnologie 3GPP tra il 3G e il 4G, cioè l’HSPA, che in Europa è arrivato a 7,2 Mbps e che, attraverso semplici aggiornamenti software può arrivare a 21 Mbps e diventare HSPA+ (HSPA Evolution). L’HSPA+ con il Mimo e il Qam 64 richiede, invece, un cambio di antenna arrivando così a 42 Mbps.
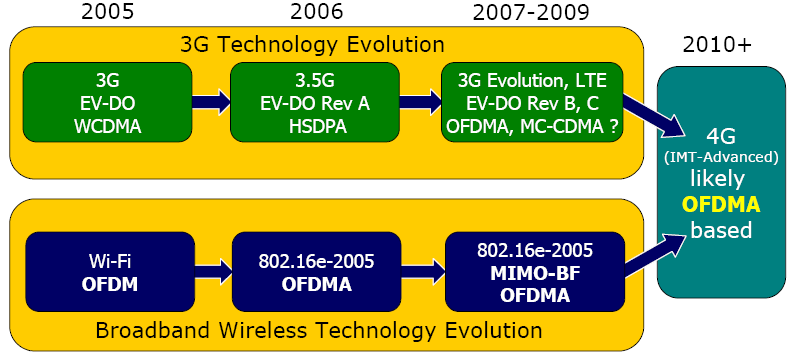
4G Evolution
— Rysavy Research
— Rysavy Research
Anche il 2,5 G continua a riservare sorprese: nel 2009 arriverà l’Evolved Edge, con velocità fino a 500 Kbps. È uno standard utile per ridurre l’abisso che c’è tra reti 2/2,5 G (tuttora le sole ad avere copertura totale in Europa) e l’Umts/Hspa.
L’architettura IMS
Il sistema è composto da molti attori che vengono raggruppati in tre insiemi (o layer) a seconda della funzione che svolgono. Per collegare questi elementi insieme c’è una varietà di protocolli, la maggior parte dei quali sviluppati in seno all’IETF (Internet Engineering Task Force, comunità internazionale di ricercatori, operatori, aziende che si occupano dell’evoluzione di internet attraverso la definizione di standard aperti). Il più importante tra questi, per la definizione di una rete IMS, è il SIP, Session Initiation Protocol, usato per la gestione delle sessioni di comunicazioni (audio, video, chat, ecc.).
Una nota molto importante di queste specifiche è che definiscono nel dettaglio i “blocchi” (detti anche function entities o service function) di cui sono composti i layer, descrivendo minutamente le varie interfacce usate all’interno del sistema per la comunicazione inter-entità. Questo permette ai singoli produttori di hardware/software di progettare soluzioni anche solo per un’entità presente nel sistema.
La rete IMS è costituita da tre strati logici, un “quarto”, non presente, è il livello utente (in pratica i terminali) che si trovano collegati al Transport Layer:
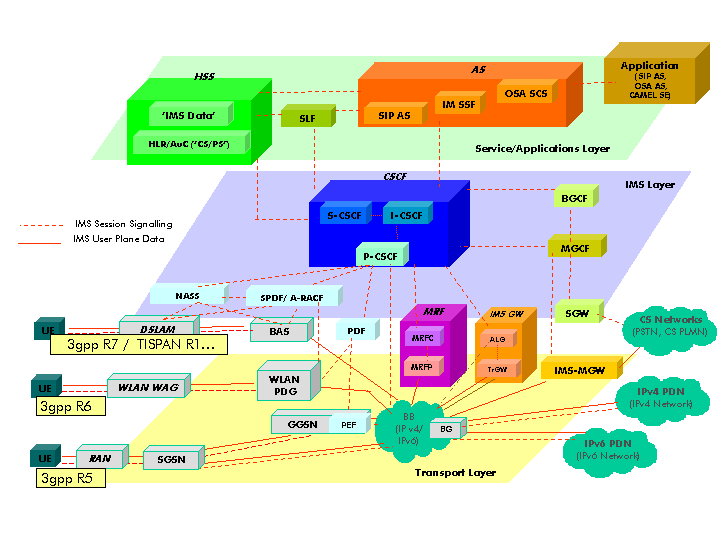
Architettura IMS
— wikipedia.org
— wikipedia.org
I tre livelli (dal basso verso l’alto):
Transport and Endpoint Layer (o Network Connectivity Layer)
È lo strato che si interfaccia direttamente con l’utente, è praticamente la porta d’ingresso per i l’iterazione dall’esterno. È su questo strato che arrivano le richieste per i nuovi servizi, che si gestisce il protocollo RTP (i flussi dati per la voce e il video) ed è qui dove risiedono i gateway per l’interfacciamento con altri tipi di rete (SMSC, Softswitch, Mediaserver, ecc.), routers, switches.
Questo strato garantisce all’accesso al sistema indipendentemente dal reale mezzo trasmissivo, quali GPRS, CDMA2000, UTMS, ADSL, W/LAN, PSTN ecc.
IMS Layer (o Session Control Layer)
È il livello che si occupa della cosiddetta segnalazione (setup e teardown delle sessioni multimediali). Ingloba i server CSCF (Call Session Control Function), che gestiscono le sessioni SIP tra gli utenti e garantiscono il QoS per i servizi offerti. Ospita il server HSS (Home Subscription Server) che mantiene i profili utente, informazioni sul roaming, servizi sottoscritti, location, e altre informazioni necessarie relative all’utente e alla rete. Contiene inoltre l’MGCF (Media Gateway Control Function) e l’MRFC (Media Resource Function Controller) necessari per le iterazioni dei media tra diversi i diversi gateway del Trasport Layer (tra cui il BGCF, Breakout Gateway Control Function per l’iterazione con le reti PSTN/SS7).
Service/Application Layer
L’Application Layer gestisce la logica di business dell’intero sistema, è la parte che ospita gli Application Server implementati secondo le specifiche SLEE, Parlay/OSA e CAMEL. Implementa i servizi di nuova generazione come instant messaging, push to talk, video streaming. Si interfaccia alla parte sottostante (Session Control) attraverso un’importante interfaccia chiamata ISC (IMS Service Control) che descriveremo alla fine della sezione.
Requisiti architetturali
L’IMS deve rispondere a dei minimi requisiti dettati dal Third Generation Partnership Project, documentati in 3GPP TS 22.228 quali:
Connettività IP
Tutti gli apparati devono essere connessi attraverso protocollo IP per accedere ai servizi IMS, sia che l’utente è direttamente collegato alla rete del proprio operatore, sia che si trovi in roaming in una visited network (la visited network è la rete dell’operatore a cui è registrato l’utente e da cui passa per accedere ai servizi che il proprio operatore gli mette a disposizione). IPv6 è preferibile.
Indipendenza dall’accesso
L’IMS è progettato per essere indipendente dal mezzo con cui si accede, cosi può offrire servizi su ogni tipo di connessione che supporti il protocollo IP, quindi dispositivi che si connettono tramite GPRS, WLAN, xDSL, ISDN.
Qualità del servizio (QoS)
Le reti IP, ma in generate le reti a commutazione di pacchetto, al contrario delle reti a commutazione di circuito, per loro natura soffrono di ritardi di:
- Elaborazione
-
ogni router/switch che si trova in mezzo ai due nodi che si intendono scambiare dati deve analizzare il pacchetto per controllare l’integrità dello stesso e determinare il corretto instradamento.
- Trasmissione
-
è il tempo necessario per la trasmissione del pacchetto che dipende dalla lunghezza del pacchetto e dalla velocità della linea di trasmissione.
- Coda
-
i pacchetti in uscita non sempre vengono trasmessi immediatamente, in quanto la linea può essere impegnata per altre comunicazioni. In questo caso in pacchetto viene mantenuto in memorie e ritrasmesso appena la linea è liberà. Più la linea è usata, e più si avranno casi di congestione come quello descritto. In generale un canale IP non riesce a sostenere oltre 80% della sua capacità trasmissivo.
A causa di questi effetti è anche possibile che pacchetti inviati tra due stessi host in instanti non molto lontani subiscano ritardi differenti. Questo ritardo è indicato col termine jitter, molto importante quando si tratta di streams multimediali che devono essere usufruiti in real-time, come una conversazione telefonica. Per questo motivo si può anche verificare la condizione che i pacchetti possono arrivare al destinatario in un ordine differente dall’invio.
Un’altra caratteristica da tenere in considerazione è la perdita dei pacchetti che può avvenire per diverse occasioni. Un pacchetto ricevuto può essere corrotto, a causa di errori o disturbi durante la trasmissione, oppure il buffer di un commutatore risulta essere saturo e quindi il pacchetto scartato, o per errori di instradamento, link down ed altre ragioni.
Per i motivi visti sopra, la rete IMS deve implementare dei meccanismi di qualità del servizio (QoS, Quality of Service) in modo tale da ridurre i casi di inefficienza nelle comunicazioni. L’IMS all’avvio di una sessione multimediale negozia tra i dispositivi dei parametri, quali:
-
Tipo di media che è possibile scambiare (Video, Audio. ecc.) e direzione.
-
Bitrate degli stream, dimensione dei pacchetti e frequenza di invio.
-
Consumo di banda.
Dopo la negoziazione, la rete riserva parte delle risorse alla sessione appena avviata fino alla sua fine. Questo è molto importante quando al servizio è associato uno SLA (Service Level Agreement, accorso sul livello del servizio) dove, se non rispettato, si applicano le relative penali.
Sicurezza delle comunicazioni
La sicurezza è uno degli aspetti fondamentali, soprattutto nelle telecomunicazioni, a cui si deve prestare attenzione. L’IMS deve fornire un livello di sicurezza maggiore, o al massimo uguale, a quello che si ha oggi sulle reti GPRS.
Ogni comunicazione che attraversa la Core Network (CN), sia in ingresso che in uscita, passa attraverso i Security Gateway (SEG) posti appunto sui bordi della rete dell’operatore e quindi applicano le policy di sicurezza definite dall’operatore stesso.
Se la Core Network è protetta con le stesse caratteristiche da tutti i punti d’accesso è anche detta Network Security Domain, NDS.
Fatturazione
Nell’IMS la fatturazione è realizzata in due modi, online e offline.
L’online charging è usato in quei servizi/sistemi preparati in cui il credito dell’utente viene via via scalato durante l’uso del servizio e interrotto al suo esaurimento. Nel secondo caso, l’offline, il servizio viene erogato e si generano solo le segnalazioni per la fatturazione, che avverrà per un relativo arco di tempo, ad esempio una volta al mese. In ogni caso, il sistema, prima di fornire un servizio, dovrà chiedere al sistema di billing se all’utente è permesso l’uso di tale servizio (procedura chiamata Credit Authorization).
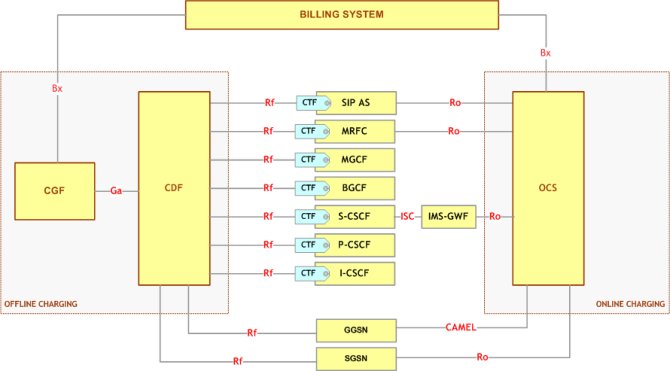
Architettura di charging IMS
— bea.com
— bea.com
Roaming
Dal punto di vista di un utente, è importante avere l’accesso ai propri servizi indipendentemente dalla posizioni in cui si trova. Il roaming dunque avviene quando un utente è connesso alla rete di un altro operatore e attraverso questa raggiunge i servizi messi a disposizione dal proprio gestore. In ambito IMS questo può avvenire in sue modi: GPRS o IMS roaming. Nel primo caso la rete a cui e connesso l’utente (visited network) fornisce l’accesso RAN e l’SGSN e la rete del proprio gestore (home network) fornisce il GGSN e l’IMS (la core network). L’IMS roaming si ha invece quando la visited network assegna la connettività IP (RAN, SGSN, GGSN e P-CSCF) e la core network del proprio operatore fornisce il resto. Il roaming IMS è preferibile in quanto utilizza in maniera ottimale le risorse che si trovano sul Connectivity Layer.
Interworking con le altre reti esistenti
L’IMS non verrà adottato da tutti gli operatori, o, per lo meno, non da tutti allo stesso tempo, né gli utenti cambiano terminale o abbonamento in maniera rapida. Per questo è stato necessario prevedere gateways per le reti più diffuse (descritti sotto) come le PSTN, ISDN, Internet.
Alcuni elementi chiave della rete IMS
Sono di seguito presentati alcuni elementi della rete IMS. Queste entità li possiamo grossolanamente classificare in sei principali categorie:
-
Gestione delle sessioni e instradamento (la famiglia dei server CSCF)
-
Database (HSS e SLF)
-
Internetworking (BGCF, MGCF, IMS-MGW, SGW)
-
Server per servizi GPRS (SGSN, GGSN)
-
Servizi (AS)
-
Gestione flussi multimediali (MRFC, MRFP)
-
Elementi di supporto (THIG, SEG, PDF)
-
Elementi per la fatturazione
P-CSCF (Proxy-Call Session Control Function)
Il P-CSCF è il proxy SIP che costituisce il primo punto di contatto tra il terminale dell’utente e l’IMS. Si può trovare nella visited network (la rete di un altro operatore) o nella home network (la propria rete) ma alcune volte è sostituito dal Session Border Controller. Il suo compito è quello di comprimete/decomprimere i messaggi SIP secondo le tre tecniche usate, validare i messaggi SIP ed esamina il contenuto SDP, inoltrare i messaggi SIP degli UE ai server I-CSCF o S-CSCF in base alla natura del messaggio, di generare i CDR (Call Detail Record) delle sessioni multimediali instaurate e di implementare le policy decision function (PDF) per autorizzare/negare determinati servizi.
I-CSCF (Interrogating-Call Session Control Function)
L’I-CSCF è un proxy SIP stateless posizionato agli estremi di un dominio amministrativo ed è un punto di contatto per tutte le connessioni destinate ad un utente in roaming attualmente all’interno dell’area coperta da un altro operatore. L’I-CSCF interroga l’HSS usando le interfacce DIAMETER Cx e Dx per ottenere la posizione dell’utente e quindi istradare le richieste SIP verso il suo S-CSCF assegnato. Fino alla Release 6, uno dei suoi ruoli era quello di nascondere la topologia della rete al mondo esterno criptando parte del messaggio SIP. In questa modalità, prende anche il nome di THIG (Topology Hiding Interface Gateway). Dalla Release 7 in poi, questa funzione viene rimossa dall’I-CSCF ed è ora parte dell’IBCF (Interconnection Border Control Function). L’IBCF è usato come gateway verso le reti esterne e fornisce delle funzioni di NAT e Firewall (pinholing).
S-CSCF (Serving-Call Session Control Function)
L’S-CSCF è il nodo centrale della rete di segnalazione, in quanto ha il compito di eseguire il setup, la modifica ed il rilascio delle sessioni multimediali su IP. L’S-CSCF si trova sempre nell’home network ed usa le interfacce Cx e Dx DIAMETER per effettuare download ed upload di user profiles dall’HSS, non avendo una memoria locale dei dati utente. In base al tipo di utenti coinvolti nella conversazione, ha la capacità di interrogare gli I-CSCF o i gateways verso la rete PSTN per garantire la conversazione tra utenti di reti diverse.
HSS (Home Subscriber Server) e SLF (Subscription Locator Function)
HSS è il database principale e contiene tutte le informazioni dei profili utente, si interfaccia con i server SIP per fornire le informazioni per le procedure di autenticazione ed autorizzazione e può fornire dati relativi alla posizione fisica dell’utente. L’HSS inoltre contiene le informazioni relative all’S-CSCF assegnato all’UE registrato.
Quando il numero di utenti diventa di grandi dimensioni, è possibile suddividere la mole di dati tra diversi server HSS. In questo caso entra in gioco il server SLF, che, interrogato prima da chi intende fare una query al database, restituisce l’indirizzo dell’HSS relativo all’utente oggetto della query.
Entrambi utilizzano il protocollo DIAMETER per scambiare informazioni con gli altri elementi dell’architettura attraverso le interfacce nominate Dh, Sh, Dx, Cx.
SGSN (Serving GPRS Support Node)
L’SGSN è il link tra l’accesso radio (RAN) e l’IP core network. È responsabile sia del controllo che del trasporto dei dati da e per il dominio PS. La parte di controllo è formata dal Mobility Management che gestisce la posizione, lo stato e l’autenticazione dell’utente e dalla parte di Session Management che si occupa della creazione della sessione dati e al suo mantenimento. Media la sessione dati tra lo UE e il GGSN fornendo un tunnel per i dati utente e assicura un QoS appropriato.
GGSN (Gateway GPRS Support Node)
La prima funzione del GGSN è dare al UE la connettività IP sulla rete esterna dove risiedono applicazioni e servizi. La “rete esterna” in questo caso può rappresentare sia la core network IMS che Internet. È del GGSN il compito di assegnare un indirizzo IP al client e contattare il PDP e il sistema di charging per le rispettive autorizzazioni e fatturazione.
L’Application Server (AS)
L’Application Server è un server SIP che ospita la logica dei servizi e li esegue, interfacciandosi con l’S-CSCF per ottenere le informazioni relative agli utenti. In base al servizio in esame, può funzionare in modalità proxy SIP, modalità SIP UA (User Agent) o in modalità SIP B2BUA (Back-to-Back User Agent). Di solito è utilizzato per gestire sessioni multiutente che coinvolgono l’impiego di risorse multimediali. In questi contesti, il suo ruolo è quello di gestire dinamicamente l’aggiunta o rimozione di partecipanti e monitorare le informazioni relative alla conferenza (e.g. tempo di inizio, durata, lista dei partecipanti e così via).
MRF (Media Resource Function)
L’MRF provvede alla gestione dei media nella home network, si usa per processare dati multimediali (audio e video), effettuare conferenze o chat con sessioni di lavoro collaborative, conversioni Text-To-Speech (TTS) e riconoscimento di linguaggio, conversione in tempo reale di dati multimediali con codifiche diverse. Ogni MRF è diviso in due unità funzionali: l’MRFC (Media Resource Function Controller) e l’MRFP (Media Resource Function Processor).
MRFC: Costituisce un nodo del piano di segnalazione, agisce come un SIP User Agent per l’S-CSCF e controlla il MRFP mediante una interfaccia H.248 MEGACO o Real-Time Streaming Protocol (RTSP). Il suo obiettivo è quello di eseguire i comandi SIP provenienti dall’S-CSCF o gli script VoiceXML provenienti dall’Application Server per creare delle sessioni multimediali di varia natura.
MRFP: costituisce un nodo del piano di media ed implementa tutte funzioni legate ai media. Nell’MRFP sono implementati dei set di codecs, transcoders e funzioni per il mix di diversi media per fornire la possibilità di manipolare l’audio ed il video nello strato di connettività. MRFP è pilotato dall’MRFC ed è diviso in media bridges per applicazioni real-time (conference bridging e transcoding) e media player per applicazioni di streaming (voice mail, notifiche di rete e servizi di informazione).
PDF (Policy Decision Function)
Il PDF è dove vengono memorizzate le regole per descrivere quali sessioni sono autorizzate e quali non in base alle informazioni ottenute dalla sessione e dai metadati provenienti dal server P-CSCF.
BGCF (Breakout Gateway Control Function)
Il BGCF è un server SIP che include la funzionalità di routing basata sui numeri di telefono. È usato soltanto quando si effettua una chiamata da un terminale IMS ad un telefono in una rete a commutazione a circuito come Public Switched Telephone Network (PSTN) o Public land mobile network (PLMN).
MGCF (Media Gateway Control Function) e IMS-MGCF (IMS-Media Gateway Function)
L’MGCF è il gateway per comunicare con le reti a commutazione di circuito (CS) PSTN, quindi è un convertitore di protocollo SIP ←→ ISUP (ISDN User Part [4], sistema di segnalazione usato sulle reti PSTN) e si appoggia alla sua controparte MGF per controllare anche il flusso audio, quindi per la conversione dei flussi audio tra la rete IMS e la PSTN (RTP PCM) e dà il necessario per fornire toni e annunci alla parte residente sulla PSTN.
SGW (Signaling Gateway)
L’SGW è un gateway per l’interconnessione alle altre tipologie di reti di segnalazione, tra SIP e SS7 (Signaling System No.7 usato nelle reti PSTN) [5]. Opera solo a livello di protocollo e non interpreta i messaggi del livello applicazione (SIP, ISUP, BICC, ecc).
SEGs (Security Gateways)
I SEGs sono entità che si posizionano sul bordo della rete IMS dell’operatore e sono usati per mettere in sicurezza le comunicazioni in ingresso e in uscita. Ce ne possono essere più di uno per tematiche relative alla fault tolerance e performance.
I protocolli alla base di IMS
Come detto precedentemente, i vari service function di cui è composto l’IMS comunicano tra di loro, e con l’esterno, usando protocolli standardizzati da IETF e ITU. Descriviamo a grandi linee quelli più importanti.
SIP – Session Initiation Protocol (RFC 3261)
Il Session Initiation Protocol gestisce in modo generale una sessione di comunicazione tra due o più entità.
Nasce in seno all’IETF per far fronte al crescente numero di applicazioni che necessitano dell’instaurazione di una sessione di comunicazione, quindi non soltanto in ambito IMS, e consente di stabilire/modificare/terminare sessioni multimediali indipendentemente dal protocollo di trasporto sottostante e dal tipo di dati (Audio, Video, Testo e/o altri).
SIP è un protocollo peer-to-peer, di tipo testuale, simile all’HTTP, e per questo permette una lettura del messaggio senza molte difficoltà dagli umani. Infatti è stato progettato tenendo sempre presente principi come la semplicità, flessibilità ed estensibilità, tipici del più noto protocollo del web, l’HTTP, contrariamente al suo SS7. Il livello di trasporto su cui si basa di default è l’UDP, con porta 5060, ma le ultime estensioni prevedono anche l’uso di TCP e SCTP. La sua funzione principale, come abbiamo già detto, è la segnalazione (gestione della sessione) ed è per questo che lavora in insieme ad altri protocolli, quali SDP e RTP, per la gestione completa della comunicazione multimediale.
Gli attori che il protocollo SIP prevede di avere sono quattro e ognuno di essi può partecipare ad una comunicazione SIP come client (colui che effettua una richiesta) o server (chi risponde) o entrambi. Un singolo dispositivo può svolgere le funzioni di uno o più attori SIP, come avviene ad esempio per un server Proxy che può svolgere funzioni si Registrar. Queste entità logiche che prevede SIP sono:
- User Agent
-
è un endpoint, come un telefono. L’User Agent si comporta sia da client che da server. La parte client (UAC, User Agent Client) inizia il dialogo SIP mentre la parte server (UAS, User Agent Server) risponde alle richieste in arrivo.
- Proxy Server
-
è un intermediario tra attori SIP. Si usa per far passare messaggi SIP tra reti diverse, quindi interpreta, e se è necessario modifica, gli stessi quando lo attraversano.
- Redirect Server
-
è un server che accetta richieste SIP e le mappa con gli indirizzi SIP del destinatario del messaggio, che possono essere zero (se il destinatario è sconosciuto dal Redirect) o più nuovi indirizzi. Diversamente dal Proxy, questo risponde al mittente della richiesta e non la passa a nessun altro. È usato quando il destinatario vuole essere rintracciato ad un’altra locazione.
- Registrar
-
è un server che accetta solo richieste di tipo REGISTER con cui l’utente notifica alla rete la sua locazione, quindi fa sapere alla rete stessa come può essere rintracciato.
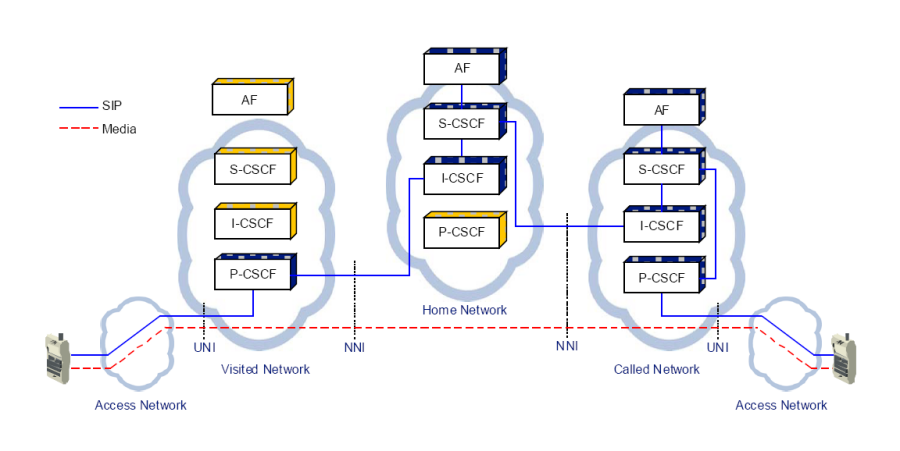
Uso tipico di SIP in ambito IMS
— DataConnection.com
— DataConnection.com
I messaggi che il protocollo prevede sono:
-
Richieste:
-
INVITE, usate per iniziare una sessione o per cambiarne i parametri (re-INVITE).
-
ACK, conferma una risposta.
-
BYE, termina una sessione.
-
CANCEL, ferma il precedente evento.
-
OPTIONS, richiede le caratteristiche supportate dalla controparte.
-
REGISTER, registra lo User Agent presso il Registrar Server.
-
INFO, manda informazioni durante una sessione senza modificarne lo stato.
-
-
Risposte, numeriche a 3 cifre di tipo:
-
Provvisorio
-
Classe 1xx, risposte provvisorie che il server trasmette per indicare lo stato di progresso della transazione SIP, ma non la terminano.
-
-
Finale:
-
Classe 2xx: indica un successo.
-
Classe 3xx: redirezione o forwarding.
-
Classe 4xx: richieste fallite (errori del client).
-
Classe 5xx: errori del server.
-
Classe 6xx: errori globali (utente occupato, non raggiungibile…)
-
-
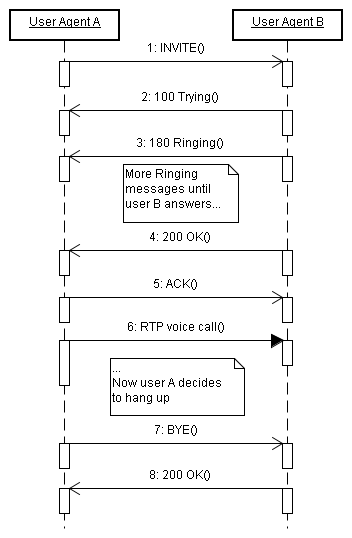
— Creazione di una sessione SIP senza intermediari tra due User Agent
SDP – Session Description Protocol (RFC 4566)
L’SDP è un protocollo testuale che descrive i parametri di inizializzazione degli multimediali. Non fornisce quindi il contenuto della comunicazione, ma semplicemente un meccanismo per la negoziazione tra il mittente e il destinatario delle codifiche utilizzate per la trasmissione dello flusso multimediale. È usato in una varietà di contesti inclusi SIP, SAP (Session Announcement Protocol) da cui è nato, RTP/RTSP, HTTP ed estensioni MIME.
Le informazioni che trasporta riguardano:
-
Il nome delle sessioni e il loro scopo
-
Tempo di vita della sessione
-
Il tipo di codec usato
-
Come ricevere il flusso (indirizzi, porte e protocolli)
-
Larghezza di banda necessaria
-
Contatti della persone responsabile della sessione.
Le informazioni sono nel formato <chiave>=<valore> e usano la codifica UTF-8.
Questo è un esempio di messaggio SIP (in alto) contenente un SDP (in basso) separati da una riga vuota:
RTP – Real-Time Protocol (RFC 3550)
É un protocollo che fornisce un servizio di trasporto dati con caratteristiche di real-time, semplificata fornitura, monitoraggio, ricostruzione, mixing e sincronizzazione di flussi audio/video.
È spesso usato su connessioni inaffidabili come l’UDP (User Datagram Protocol), non fornisce QoS, prenotazioni di risorse, ma sincronizzazione tra flussi multimediali, verifica dei pacchetti persi per una stima della qualità, riordino dei pacchetti all’arrivo. È stato ideato sia per trasmissioni unicast che multicast.
Non ha porte di default e questo rende necessario l’uso di un altro protocollo, STUN (Simple traversal of UDP over NATs), quando siamo in presenza di una rete con NAT. È spesso usato in congiunzione con RTCP (Real-time Transport Control Protocol), definito nella stessa RFC, che raccoglie statistiche sulla qualità del servizio, informazioni sui partecipanti, byte trasferiti, jitter, round trip delay, ecc. in una connessione parallela all’RTP.
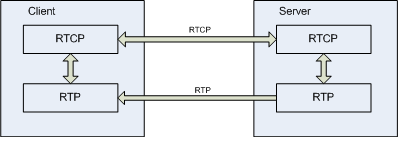
— Connessioni in un trasferimento multimediale one-way
Diameter (RFC 3588)
Il Diameter è il protocollo che implementa i meccanismi di Authentication, Authorization e Accounting (AAA). Definito nell’RFC 3588, il funzionamento di base prevede un’architettura peer-to-peer e l’uso di protocolli di trasporto come TCP o SCTP.
Il nome Diameter deriva da un gioco di parole riferito al protocollo che va a sostituire ed estendere, il Radius (Remote Authentication Dial-In User Service). Rispetto a questo migliora il protocollo di trasporto, che ora si basa sui più affidabili TCP o SCTP rispetto all’UDP, la sicurezza (posso essere impiegati IPsec e TLS), l’estendibilità (adesso sono presenti 32 bit per indirizzare il nome di un parametro contro 8 dei precedenti), la scoperta automatica di nuovi peer (usando i record DNS SRV e NAPTR), la gestione degli errori e molto altro.
Il protocollo Diameter definisce un appoggio su cui sviluppare ulteriori protocolli, infatti le specifiche Diameter Base precisano la capacità di stabilire connessioni tra i peer, il routing tra di essi, la gestione delle sessioni, il rilevamento di connessioni cadute, ecc. ma sono necessarie estensioni specifiche per i servizi che si vogliono usare, alcune sono:
- Mobile IP
-
permette lo scambio di informazioni tra le reti a cui il terminale mobile si aggancia duramente i suoi spostamenti.
- NASREQ (Network Access Server Requirements)
-
è usata per fornire servizi di AAA in modalità dial-in PPP (Point-to-Point Protocol).
- Ro Application
-
accounting di tipo on-line.
- Rf Application
-
accounting off-line.
- Sh Application
-
richieste tra Application Server e HSS.
Le estensioni Diameter non sono altro che un insieme di parametri a cui è associato un valore, i cosiddetti AVP (Attribute Value Pair). Questi non solo altro che una rappresentazione di dati come nome-valore, progettati per prendere la struttura che li contiene (in questo caso il messaggio Diameter) aperto ad estensioni e futuri cambiamenti senza la necessità di modificare il codice che lo gestisce.
Dato che si tratta di un protocollo p2p, ogni host che implementa il protocollo Diameter opera sia come client che come server per questo ci si riferisce all’host col termine nodo. Nonostante questo, viene denominato client il peer che effettua la richiesta e server colui che risponde. Come nel caso di SIP, anche nel Diameter un nodo può rappresentare una o più funzione logiche, cosi oltre al client ed al server esistono degli Agent. Gli Agent sono nodi che introducono flessibilità all’architettura, hanno svariati scopi tra cui quello di concentrare le richieste di un vasto gruppo di Diameter client in pochi nodi della rete, load balancing, redirezione delle richieste ecc.
Esistono diversi tipi di Agent:
- Relay Agent
-
è usato per spedire il messaggio alla destinazione corretta basandosi sulle informazioni che il messaggio stesso contiene. È vantaggioso usarlo quando si vogliono aggregare richieste provenienti da domini diversi (Realm) ad una specifica destinazione eliminando la necessità di configurazioni multiple.
- Proxy Agent
-
sono molto simili ai Relay ma con più funzionalità. Infatti i Proxy Agent oltre a rigirare le richieste ai server di destinazione, sono in grado di verificare lo stato di collegamento con i peer, attuare politiche di load balancing ed è in grado di modificare il contenuto del messaggio in base a determinate politiche.
- Redirect Agent
-
non fa altro che rispondere alle richieste indicando al mittente il server che è in grado di soddisfarle. Rappresenta in un certo senso un repository centralizzato per la configurazione dei nodi Diameter. È molto utile in quegli scenari in cui sono presenti molti Proxy Agent e non si vuole replicare la configurazione dei nodi-realm su ognuno di essi.
- Translation Agent
-
come il nome fa immaginare, questo tipo di Agent converte i messaggi diameter in altri formati. È utile in quei casi in cui il passaggio a Diameter avviene in fasi graduali e i nuovi sistemi devono poter interfacciarsi con i vecchi. Nella maggior parte dei casi la traduzione avviene tra Diameter e Radium o tra Diameter e TACACS+, che sono gli altri due protocolli di AAA a sui Diameter si sostituisce.
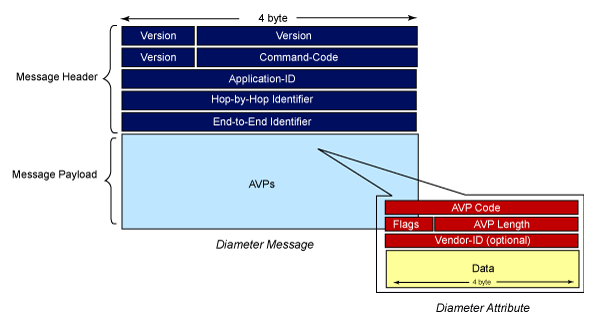
Messaggio Diameter
— ibm.com
— ibm.com
L’interfaccia ISC (IMS Service Control)
Questo è un paragrafo fondamentale per capire il collegamento esistente tra l’architettura IMS che gli operatori si stanno attrezzando a implementare e descritta fin qui con le specifiche JAIN SLEE della SUN presentare nella parte successiva.
Ricordando l’architettura dell’IMS (Figura 7), possiamo notare che nel Service/Application Layer sono preseti i server che implementano le logiche di business. Questi server sono collegati ai server CSCF attraverso l’interfaccia denominata ISC, che trasporta messaggi SIP, e possono operare come SIP UA (User Agent), SIP B2BUA (Back-to-Back User Agent), Conference server, Presence server ed offrire molti altri servizi. Sono anche collegati ai server HSS/SLF attraverso le interfacce Sh, Ro, ed Rf, basate su Diameter, per recuperare e memorizzare informazioni relative alla rete e agli utenti e per fornire informazioni al sistema di fatturazione relativamente ai servizi offerti.
Le procedure che coinvolgono l’ISC si possono dividere in due categorie:
-
Richieste che partono da elementi di rete o da utenti, e che, attraverso l’S-CSCF, possono raggiungere l’AS. L’S-CSCF inoltra le richieste all’AS in base all’analisi del messaggio SIP e alle politiche che vengono implementate dalla rete. In questi casi, l’AS può terminare, ridirigere e proxare richieste SIP, anche ad altri AS sempre attraverso gli S-CSCF. Scenari come Text-To-Speak o Richiamata su occupato appartengono a questa categoria.
-
Richieste per partano dall’AS, quindi l’AS come inizializzatore della sessione. Questo caso raggruppa gli scenari in cui l’AS è visto come un SIP User Agent, o che si comporta come un Back-to-Back User Agent.
In riferimento al primo caso descritto, quando è l’S-CSCF a contattare l’AS, lo fa basandosi su quello che viene definito Initial Filter Criteria (IFC). Questi non sono altro che parametri memorizzati nel profilo utente (quindi residenti nell’HSS), sezione service-triggering, e dipendenti dai servizi che l’utente (chiamante o chiamato) ha sottoscritto.
Oltre a descrivere il servizio in base al quale attivarsi, contengono informazioni sull’AS a cui girare la richiesta, la priorità con cui devono essere eseguiti i servizi che si attivano su identici avvenimenti, informazioni relative ai casi in cui si ha un AS che non risponde, e poche altre.
Sempre in riferimento al caso in cui è l’AS a ricevere una richiesta dall’S-CSCF, il comportamento che può assumere l’AS stesso si può riassumere in quattro punti:
-
Terminating UA: l’AS assume il comportamento di un UE (Figura 13, freccia rossa). È usata ad esempio nel caso della voicemail o per gestire la propria presenza in rete su un server di Presence.
-
Redirect server: l’AS informerà il mittente sulla nuova destinazione a cui è possibile raggiungere l’utente.
-
SIP Proxy: si comporta a tutti gli effetti come un proxy SIP e è in grado di aggiungere, rimuovere o modificare gli header contenuti nella richiesta SIP.
-
Third-party call control/B2BUA: l’AS genererà uno nuovo dialogo SIP e si comporterà come un back-to-back User Agent. In questo caso ha un maggiore controllo della sessione rispetto al caso precedente (in blu nella figura).
Da notare nella Figura 13 che in nero è il caso in cui né il chiamato né il chiamante hanno sottoscritto servizi aggiuntivi, situazione di una semplice chiamata base. Mentre in verde si nota la reazione che vede l’AS iniziatore del dialogo SIP, ad esempio nel caso in cui, sempre relativamente ad un caso di presenza, il Presence Server (AS) notifica ad un utente il cambiamento di stato di un contatto.
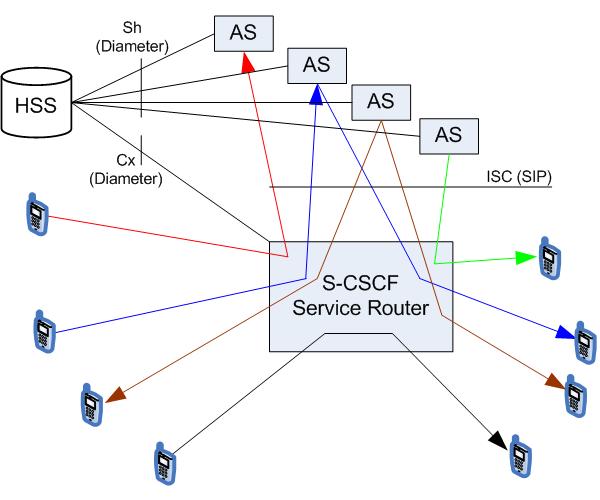
— Iterazione tra S-CSCF e Application Servers

Parte Seconda: JAIN SLEE e Mobicents
Dopo aver visto, seppur a grandi linee, l’intera architettura IMS andiamo ad approfondire il punto in cui risiederanno le logiche di business. L’Application Server che andremo ad analizzare implementa le specifiche JAIN SLEE, Java APIs for Advanced Intelligent Networks Service Logic Execution Environment. Questo può essere utilizzato come Applicationi Server in ambito IMS per la gestione ed erogazione dei servizi intelligenti.
SLEE, attraverso i suoi connettori denominati Resource Adaptor, si interfaccia tramite Sip e Diameter (con i protocolli ISC ed Sh rispettivamente) col mondo IMS.
La descrizione dei moduli da cui è composto JAIN SLEE, del modo in cui avviene l’interazione tra di essi e col mondo esterno alla piattaforma SLEE e di Mobicents (la prima e sola piattaforma open source certificata che implementa questa tecnologia) sono trattati nella presente sezione.
la JAIN Initiative
Java è sinonimo di modularità, interfacce standard, portabilità delle applicazioni da piccoli dispositivi a grossi cluster di server, ma soprattutto di Java Application Programming Interfaces (APIs). Queste ultime sono necessarie per fornire un adeguato livello di astrazione tra moduli software anche sviluppati da diversi enti.
Tutto questo nel mondo delle telecomunicazioni è racchiuso nel nome JAIN, Java APIs for Intelligent Network o anche Java APIs for Integrated Network.
La “JAIN Initiative”, come viene spesso definita, è una comunità di esperti nell’ambito delle telecomunicazioni uniti per definire un insieme di tecnologie che danno la possibilità di sviluppare rapidamente prodotti e servizi per le reti di nuova generation, le cosiddette NGN. Questa unione si è resa sempre più necessaria dall’esordio delle tecnologie di seconda e terza generazione (2.5G e 3G). Le architetture erano, come abbiamo già visto, verticalmente e non condividevano uno standard collettivo per integrarsi e fornire servizi più complessi. JAIN fa della portabilità, indipendenza dalla rete e dello sviluppo aperto i suoi cavalli di battaglia per portare un nuovo livello di astrazione nei servizi integrati internet/telefono che renderà la creazione di migliaia di servizi innovativi un processo semplicissimo rispetto ad oggi.
Le API sviluppate in seno alla JAIN Initiative includono, tra le altre cose, API per il controllo delle chiamate, messaggi (instant messaging), presence, servizi basati sulla posizione.
L’iniziativa vede Sun come società leader nel progetto di sviluppo di queste tecnologie, progetto che va sotto il nome di Java Specification Participation Agreement (JSPA) e Java Community Process (JCP), accompagnata da altri colossi come IBM, Motorola, NTT DoCoMo e Vodafone.
Obiettivi
Gli obiettivi con cui la JAIN Initiative intende realizzare la propria infrastruttura e far convergere gli operatori al proprio modus operandi sono:
-
Service portability - portabilità di un servizio da una piattaforma all’altra grazie alla standardizzazione delle API.
-
Network convergence - convergenza delle comunicazioni grazie all’astrazione fornita dalle API, quindi indipendenza dal mezzo di comunicazione (es. SS7 o IP e grazie all’IMS).
-
Service Provider Access - permettendo alle applicazioni che girano fuori dal dominio dell’operatore di interagire in maniera sicura e controllata al network del provider sfruttando le nuove possibilità di accesso.
Questi sono gli stessi punti che hanno portato al successo la piattaforma J2EE nell’industria IT. La rimozione delle soluzioni proprietarie e la standardizzazione verso soluzioni open semplificherà lo sviluppo e l’installazione di nuove componenti java, tutto a minor prezzo. Da parte dei Network Operator si avrà una maggiore competitività nel fornire soluzioni in tempi più brevi e potranno scegliere i loro fornitori di componenti da un vasto bacino in base a funzionalità e valore aggiunto.
Le componenti di JAIN
Oltre a SLEE, la JAIN iniziative ha standardizzato API come:
-
JAIN Session Initiation Protocol (JSIP) – è la definizione di uno stack SIP in Java che fornisce i meccanismi base del protocollo SIP da implementare in gateway, client, server. Questo non include le funzionalità per la gestione del flusso multimediale, ma ha tutto il necessario per realizzare User Agent, Proxy, Registrar e Redirect Server.
-
Java Call Control (JCC) – è una libreria che permette la gestione, il monitoraggio, l’inizializzazione, la risposta e l’elaborazione di chiamate multimediali (voce e/o video). Le applicazioni che fruttano questa libreria si occupano solo di gestire l’interfacciamento all’API, sarà quest’ultima a interagire le reti sottostanti indipendentemente dalla loro tipologia (wireless, wireline e Internet).
-
Server APIs for Mobile System (SAMS) – sono le APIs che gestiscono messaggi (SMS e MMS), presenza e posizione dei terminali mobili lato server.
-
Mobile Device Management and Monitoring (DM) – permettono il monitoraggio, la gestione della configurazione, dei software e delle librerie installate dei dispositivi mobili da un punto centrale, i server dell’operatore al quale il device si sincronizza.
-
SIP for J2ME – sono delle API che forniscono alla piattaforma J2ME la possibilità di connettersi via SIP e poter effettuare chiamate. Sono basate sul Generic Connection Framework del J2ME Connecter Limiter Device Configuration (CLDC) ed usano le esistenti classi di I/O del CLDC.
-
Location for J2ME – permettono agli sviluppatori della piattaforma J2ME di conoscere la posizione del dispositivo. È sempre basata su CLDC.
-
Wireless Messaging API (WMA) – fornisce l’accesso, sempre da J2ME (sia CLDC che MIDP), al sottosistema wireless del dispositivo. Da l’accesso al Unstructured Supplementary Service Data (USSD) e al Cell Broadcast Service (CBS) per scambiare lo scambio di dati o per ricevere le informazioni che la stazione base trasmette in modalità broadcast.
JAIN Service Logic Execution Environment
Lo SLEE definisce un modello di architettura orientata a componenti per la creazione di logiche applicative, non solo di servizi di comunicazione, ma di tutte quelle applicazioni che possono essere guidate da eventi e/o messaggi ed hanno elevati throughput mantenendo bassi tempi di risposta.
Le specifiche non definiscono l’implementazione di SLEE né la tecnologia sottostante, bensì le interfacce, le relazioni tra esse e le iterazioni con l’ambiente host che esegue SLEE, lasciando liberi i produttori di differenziare i loro prodotti e favorire la concorrenza tra tecnologie diverse.
Grazie alla standardizzazione di queste interfacce, le applicazioni sviluppate con SLEE possono essere formate da una collezione di oggetti riusabili che a loro volta possono essere applicazioni SLEE. Questo facilita la creazione e la composizione di servizi sempre più complessi.
JSLEE prevede meccanismi di scalabilità, performance e robustezza anche se non definisce particolari strategie con cui concretamente realizzare queste caratteristiche. Un server che implementa le specifiche SLEE rappresenta quindi un container per lo sviluppo di applicazioni guidate da eventi o messaggi asincroni. Questo, come vedremo, è un aspetto molto importante del sistema poiché si distingue dalle altre specifiche che usano una logica di risposta sincrona, come le Sip Servlet.
In aggiunta al modello a componenti, JSLEE definisce l’interfaccia di gestione amministrativa dell’Application Server e un set di “Facilities”. Quest’ultimi forniscono allo sviluppatore di servizi una serie di funzioni di utilità per le operazioni più comuni.
Al processo di sviluppo sono intervenuti, oltre alla SUN, anche i contributi provenienti da società del settore TLC e non, come Open Cloud, jNetX, Telecom Italia, Università di Genova, Telecordia, NIST ed altre.
Gli obiettivi
Questa piattaforma mira a:
-
Definire uno standard per lo sviluppo di applicazioni di comunicazione object-oriented a componenti nel linguaggio di programmazione JAVA.
-
A sviluppare applicazioni che si combinano, o che sono basate, su componenti sviluppati con altri tool o da differenti aziende.
-
A nascondere lo strato sottostante la definizione del servizio stesso: lo sviluppatore non è tenuto a conoscere o gestire dettagli quali il multi-threading, connection pooling, transazioni e altre api di basso livello.
-
Grazie all’uso di Java e alla filosofia Write Once, Run Anywhere™, le applicazioni scritte e compilate per una determinata piattaforma conforme a SLEE “dovrebbero” (il condizionale è sempre d’obbligo) essere installati ed eseguiti un qualunque altra piattaforma senza modificare o ricompilare il codice sorgente.
-
Facilitare gli aspetti di sviluppo, installazione e configurazione e ciclo di vita delle applicazione telecom.
-
Definire le interfacce per un’architettura a plug-in dei Resource Adaptor per facilitare lo sviluppo e la portabilità nelle differenti implementazioni di JSLEE.
-
Definire le interfacce che facilitano l’interoperabilità tra applicazioni sviluppate da vendors diversi.
-
Compatibilità con J2EE: sia JSLEE che i server J2EE devono poter convivere nello stesso sistema e collaborare per fornire servizi integrati e convergenti (internet e telefonia, SIP e HTTP).
-
Compatibilità con le specifiche Java Management Extensions (JMX) per la gestione dell’application server.
Il rapporto con J2EE
Java 2 Enterprise Edition è la piattaforma Java per le applicazioni che hanno elevati requisiti di stabilità, sicurezza, coerenza (transazionalità) e performance. È la risposta della Sun alle richieste di un sistema robusto, stabile e flessibile, mantenendo delle specifiche aperte per favorire l’integrazione di prodotti create da differenti case. Queste non solo altro che delle (consistenti) specifiche, le “solite” API, che mirano prima di tutto alla creazione di un ambiente data centrico.
SLEE è standardizzato per venire incontro alle richieste di real-time e di grandi throughput come il mondo delle comunicazioni può richiedere. JSLEE non è progettato per sostituire J2EE, né viceversa, bensì per integrarsi con esso e fornire un insieme completo di features, dando al mondo enterprise di J2EE meccanismi per l’elaborazione tipici di una piattaforma guidata ad eventi (event driven).
| Caratteristica | J2EE | JSLEE |
|---|---|---|
|
Tempo medio di esecuzione di una richiesta |
< 2 secondi Non real-time |
< 100 msec Soft real-time |
|
Media Transazioni completate |
1000/sec |
10000/sec |
|
Uptime |
99.9% (9 ore/anno) |
99.999% (5 min/anno) |
|
Esecuzione servizi (tipica) |
Sincrona |
Asincrona |
|
Modello transazionale |
Orientato al database, quindi pesanti e lente |
Piccole transazioni per la delimitazione della replica nel cluster, frequenti |
|
Persistenza |
Databases, EIS |
In memoria |
JAIN SLEE ha, come vedremo, implementato internamente un meccanismo di code su cui si basa il suo intero funzionamento. Alcuni possono obiettare che anche in J2EE esista un qualcosa di simile, e precisamente JMS. Benché lo scopo delle due code sia identico, in SLEE la creazione, distruzione e associazione ai consumer delle code è qualcosa che viene gestito dal container con centinaia di iterazioni al secondo. In JMS le cose vanno diversamente, in quanto le code (o i topics) vanno dichiarate nel setup dell’application server e persistono per tutta la vita del container.
Dopotutto le due tecnologie possono essere intergrate per usi specifici attraverso un adattatore SLEE←→JMS che permette lo scambio di messaggi tra i due ambienti.
La relazione con le SIP Servlet
Mentre JSLEE è un application server, le SIP Servlet (JSR 116) sono un’estensione del modello HTTP Servlet al mondo SIP. Sono state realizzare per semplificare la scrittura di applicazioni SIP (data la relazione con le Servlet) ed attrarre cosi più sviluppatori, fornendo solo uno stato software che fa da wrapper allo stack SIP implementato a più basso livello. Sono due tecnologie per sviluppare applicazioni SIP molto diverse. Una completa e modulare (JSLEE), l’altra piccola, leggera, rapida nella sua acquisizione, ma alcune volte scarna per aspetti importati (Sip Servlet). Naturalmente la scelta di una o dell’altra tecnologia è molto dipendente da ciò che si andrà a realizzare, ecco quindi una piccola lista delle differenze esistenti:
-
JSLEE astrae il livello di rete sottostante, SIP Servlet no.
-
JSLEE è molto più complesso delle SIP Servlet.
-
JSLEE supporta le transazioni, SIP Servlet no.
-
JSLEE definisce molte facility rispetto alla sola timer facility di SIP Servlet.
-
JSLEE definisce la gestione di manica si servizi e dati utente, SIP Servlet no.
-
JSLEE è molto più versatile e potente delle SIP Servlet, al costo della semplicità.
Integrazione di JAIN SLEE nel mondo TLC
Lo SLEE è adatto, date le sue caratteristiche, a una varietà di ambienti di comunicazione.
Infatti è in grado di interfacciarsi con:
-
Tecnologie di segnalazione tradizionali come SS7, ma anche le nuove 3G e NGN.
-
Tramite gateway Parlay/OSA/JSPA a reti già implementate che accettano AS tramite queste interfacce.
-
OSS/BSS (Operational and Business Support Systems) per fornire agli operatori e gestori delle reti un ambiente per la creazione e manutenzione dei servizi in maniera rapida ed efficiente (SCE, Service Creation Environment).
-
Server J2EE contenenti servizi già presenti in rete.
-
Sistemi di middleware, ed integrarsi con essi per fornire un completo ambiente per la realizzazione di servizi innovativi e complessi.
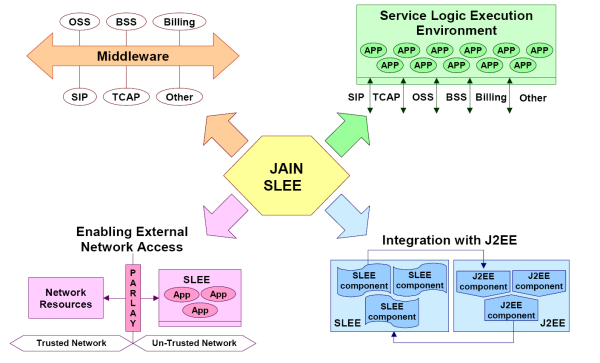
Integrazione di JAIN SLEE con gli ambienti esistenti
— OpenCloud.com
— OpenCloud.com
L’architettura
SLEE è formato da una serie di componenti che permettono l’esecuzione dei servizi in maniera asincrona , event-driven application.
Di seguito possiamo osservare a grandi linee com’è composto JAIN SLEE (Figura 15). Possiamo osservare verticalmente le Facilities, che forniscono ai servizi (al centro) i metodi per gestire efficacemente e facilmente alcune funzioni tra le più comuni. Dal lato opposto, sempre verticalmente, è presente la Management Interface che si occupa della gestione e configurazione di servizi, risorse e modalità di funzionamento. Sotto possiamo trovare lo strato di Resource Adaptor, componenti dello SLEE che si occupano di astrarre l’architettura di rete e protocolli per presentare una “vista” Java delle risorse che si andrà ad utilizzare. Al centro possiamo osservare i servizi che sono installati internamente al container e la parte di Event Router, il processo che decide, in base ai messaggi in arrivo, ai servizi presenti e al loro ordine di priorità, dove dirottare i nuovi messaggi.
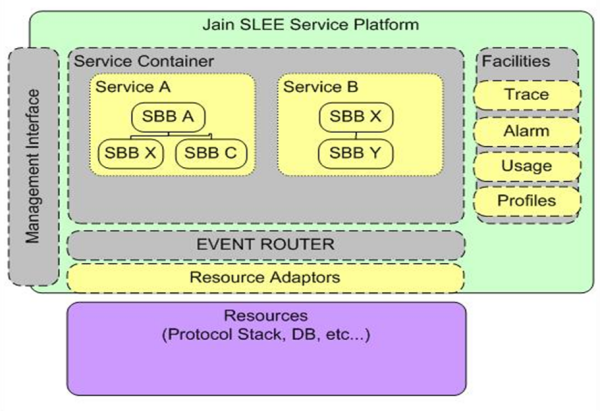
Architettura semplificata di JSLEE
— jboss.org
— jboss.org
SLEE definisce anche le interfacce per la memorizzazione dei dati relativi alla configurazione e di quelli relativi ai profili utenti, nascondendo come di consueto l’implementazione sottostante. Sarà quindi possibile salvare dati in XML, Database, Directory LDAP e molti altri tipi di storage usando le stesse procedure.
Per poter comunicare con l’esterno, lo SLEE deve avere degli adattatori di protocollo per le varie risorse a cui necessita interfacciarsi. Questi adattatori vengono chiamati Resource Adaptor (RA) e sono composti da un descrittore che definisce l’interfaccia per accedere alla risorsa, dalle notifiche che la stessa può lanciare e dall’implementazione vera e propria dell’adattatore.
È necessario inoltre creare dei pacchetti di installazione per le Applicazioni e per i componenti che la compongono e per Resource Type in maniera standard come definito nelle specifiche, corredandoli con descrittori XML.
SLEE supporta anche le transazioni per il controllo della concorrenza, estendendo il modello definito nelle Java Transaction API [7] con alcune caratteristiche asincrone, supportando solo le transazioni locali.
Eventi e tipi di evento
Un evento (event) è un “qualcosa” che deve essere elaborato. Questo qualcosa porta con se informazioni che descrivono chi ha generato questa richiesta, la priorità con cui elaborarla ed altri dati necessari alla sua evasione. Un evento può essere generato da:
-
Una risorsa esterna allo SLEE, come un richiesta SIP.
-
Internamente allo SLEE. Come abbiamo precedentemente sottolineato, trattandosi di un Application Server event-driven, lo SLEE stesso per cambiare il proprio stato interno emette eventi. Ad esempio, il Timer Facility emette un evento quando il timer scade.
-
Un’applicazione che è eseguita in SLEE. Le applicazione installate in SLEE possono a loro volta emettere eventi per notificare altre applicazioni o per mandare messaggi esternamente, come nel caso di una risposta SIP.
Ogni evento in SLEE ha associato un event-type che descrive come tale evento deve essere gestito.
Activity
Per l’esecuzione corretta di un servizio è necessario prevedere un sistema che leghi in qualche modo insieme gli eventi relativi allo stesso flusso di servizio. Ad esempio, se arriva un messaggio di BYE causato dall’abbattimento di una sessione multimediale (tipico esempio, la chiusura del telefono) lo SLEE deve sapere oltre a come gestire il messaggio, anche a quale istanza di servizio attualmente in esecuzione appartiene. Per far ciò usa quello che viene chiamata Activity. Un’Activity viene definita dal Resource Adaptor a cui fa riferimento e rappresenta una iterazione o flusso di servizio che l’RA gestisce. Ad esempio, per l’invio di un SMS si usa il protocollo SMPP. L’iterazione in questo caso può essere formata dal messaggio che viene spedito dall’RA e dalla relativa risposta dal server SMPP. Questi due messaggi appartengono alla stessa Activity.
Le applicazioni in SLEE
Sono ovviamente applicazioni orientati agli eventi che non hanno la necessità di attivare dei threads per l’esecuzione delle operazioni, ma usano quello del container che ha sollevato l’evento. Infatti, l’applicazione mette a disposizione del container il metodo da richiamare per l’elaborazione della richiesta che può a sua volta emettere un evento, interagire con la risorsa che ha originato l’evento, o aggiornare lo stato interno dell’applicazione. Tipiche applicazioni SLEE sono quelle che al loro interno implementano una macchina a stati [6]. Ogni cambiamento di stato è determinato da un evento. L’applicazione, tramite la descrizione, in formato XML, degli eventi che è in grado di ricevere (gli event-types) fornisce allo SLEE il meccanismo per la scelta del metodo da invocare in base all’evento occorso. Le applicazioni vengono costruite collegando insieme i componenti che rappresentano i vari eventi. Questi componenti sono chiamati Service Building Block (SBB) e contengono al loro interno un codice per gestire l’evento a cui dichiarano di essere interessati. Gli SBB possono anche dichiarare delle interfacce per il richiamo dei loro metodi in maniera sincrona. In run-time, SLEE alla ricezione di un evento, verifica gli SBB da richiamare (in base al loro event-type), instanzia l’SBB scelto e gli notifica il messaggio. L’SBB, finita l’elaborazione, passa in uno stato di disattivazione finché il container non lo distrugge.
Service Building Block – SBB
L’SBB è il componente centrale nello sviluppo di applicazioni JAIN SLEE. Il Service Building Block rappresenta un elemento riutilizzabile per la creazione dei servizi, infatti il servizio stesso è la composizione di vari SBB collegati da relazione padre-figlio.
A destra possiamo osservare un grafo in sui i nodi (formati da ellissi) rappresentano degli SBB e degli archi sono la relazione padre-figlio tra essi.
— Relazioni tra SBB
Il numero sull’arco è la priorità assegnata alla relazione. La direzione della freccia indica il verso della relazione, ad esempio vediamo che X è il padre di Y. È possibile anche definire degli SBB che si riferiscono a loro stessi per la relazione, come avviene nel caso di Z in cui lo stesso SBB è il padre di se stesso. Un SBB può avere zero o più figli, ma dato che può essere creato da un solo oggetto, potrà avere un solo padre.
Un SBB è composto da:
-
Event-types che descrivono degli eventi che il componente è in grado di ricevere e lanciare.
-
I metodi relativi agli eventi a cui l’SBB è interessato (uno per evento).
-
La SBBLocalInterface che contiene i metodi che è possibile richiamare sull’SBB in maniera sincrona. Questa interfaccia è disponibile solo per gli SBB che appartengono allo stesso servizio.
-
Le Child relation, le relazioni padre-figlio con gli altri SBB e le relative priorità. Queste priorità vengono usare da SLEE per ordinare l’attivazione di un evento che, forcandosi, impatta su più SBB fratelli.
-
Dati condivisi con altri SBB, memorizzati sull’Activity Context (vedi 1.6.4). l’SBB fornisce un’interfaccia per accedere a questi dati in modalità sicura con dei getter e setter.
Un’altra caratteristica degli SBB è che alcuni possono essere Root SBB. Questi, a differenza degli altri, possono essere istanziati dallo SLEE attraverso un degli Initial event type che l’SBB mette a disposizione. Vengono indicati come root perché sono gli SBB che vengono attivati per primi nell’esecuzione di un’istanza di servizio. Quindi da loro avrà origine il grafo del servizio che attraversa i vari SBB da cui è composto, come nel caso di X1, X2 e Z2 in Figura 16. L’esecuzione di un servizio determina quello che nelle specifiche è chiamato SBB Entity Tree e che è schematizzato come un grafo aciclico.
— Esempio di Servizio JAIN SLEE
Lo SLEE è responsabile della sola creazione e attivazione del Root SBB (l’istanza di un SBB viene chiamata SBB Entity) ma è anche possibile che il Root SBB sia istanziato da un altro SBB.
Ad esempio, se esistono due servizi, CallBlocking e CallForwarding che si attivano indipendentemente e si vuole realizzare un servizio di CallBlockingAndForwarding, lo sviluppatore del servizio può creare un Root SBB relativo al CallBlockingAndForwarding che ha come figli i Root SBB di CallBlocking e CallForwarding.
La figura fa notare anche il ruolo di SLEE nell’avvio del servizio, è inteso come padre logico del Root SBB che sta attivando.
Il ciclo di vita di un SBB può essere rappresentato come in Figura 18:
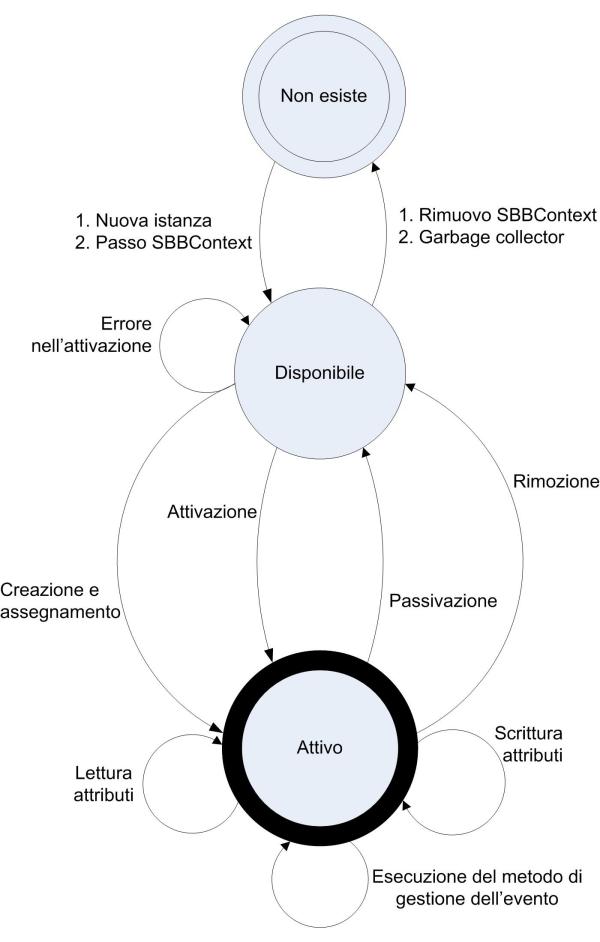
— Ciclo di vita di un SBB
Nonostante abbia solo tre stati, il meccanismo di creazione/attivazione è complesso per venire incontro alle esigenze di scalabilità e prestazionali di SLEE.
La creazione dell’SBB avviene quando lo SLEE lo crea usando la tipica “new Object” di java sull’oggetto. Alla creazione viene richiamato sull’oggetto il metodo setSbbContext che passa al nuovo SBB il contesto su cui andrà a lavorare (si tratta di un oggetto di tipo SBBContext appartenente allo SLEE che mantiene informazioni sul tipo di servizio a cui l’SBB è associato, su SLEE e permette di richiamare delle funzioni fornite da SLEE).
L’SBB sarà quindi nello stato disponibile (Pooled) e messo in un “contenitore” (il Pool appunto) di SBB. Ogni tipo di SBB ha il suo pool dove verranno aggiunti SBB tutti della stessa natura, indifferenziati, nessuno collegato a particolari servizi. Dato che tutti gli SBB nel pool sono equivalenti, quando lo SLEE deve elaborare un evento andrà a recuperare un’istanza di SBB da questo pool. Ci sono due possibilità di attivazione dell’SBB:
- Creazione e assegnamento
-
quando l’SBB è assegnato da una nuova SBB Entity appena creta da un SBB padre o implicitamente dallo SLEE per gestire un Initial Event (richiamando i metodi sbbCreate e sbbPostCreate sull’SBB).
- Attivazione
-
per gli altri casi in cui l’SBB Entity esiste già. Accade quando non ci sono SBB in stato Attivo assegnati all’SBB Entity e disponibili per ricevere l’evento da elaborare (richiamando il metodo sbbActivate sull’SBB).
Quando un SBB si trova nello stato Attivo è associato ad un SBB Entity. Lo SLEE può richiamare quindi i metodi per la lettura e il salvataggio degli attributi sull’SBB Entity per la sincronizzazione dello stato interno dell’SBB. Così lo SLEE può richiamare sull’SBB tutto ciò che l’SBB stesso fornisce: metodi per la gestione degli eventi, ottenere interfacce locali per le chiamate sincrone, ecc.
Se lo SLEE vuole dissociare l’SBB dalla relativa SBB Entity, per esempio perché l’SBB non è più interessato a ricevere eventi, si procede con la passivazione (Passivate) che scollega l’SBB dall’SBB Entity a cui era collegato e permette la riassegnazione dell’SBB ad un’altra SBB Entity. Prima di riportare l’SBB nel pool, lo SLEE richiama il metodo sbbStore per la sincronizzazione dello stato interno sull’SBB Entity. A questo punto lo SLEE invoca sbbPassivate e sposta l’SBB nel pool assegnandogli lo stato di Pooled. È possibile che l’SBB passi allo stato disponibile attraverso un’altra via. Infatti è possibile che l’SBB venga rimosso perché il servizio termina o perché una parte dell’SBB Tree non è soggetta a ulteriori elaborazioni e SLEE decide di terminarla e di rimuoverla dall’albero degli SBB (Figura 17): in questo caso viene richiamata la sbbRemove dell’SBB subito dopo la sua sincronizzazione con l’SBB Entity.
Lo SLEE può decidere di alleggerire il pool di SBB creati per vari motivi, ad esempio per liberare memoria/risorse. In questo caso richiama semplicemente la unsetSbbContext dell’SBB e lo rende così disponibile al garbage collector di java per la sua rimozione dalla JVM.
È da sottolineare un aspetto importante per il multithreading in SLEE: un SBB può elaborare un solo evento per servizio per volta ma è possibile far lavorare diversi SBB dello stesso servizio in modo parallelo su eventi diversi.
Activity e Activity Context
Un Activity rappresenta uno flusso di eventi relazionati tra essi. Questi eventi derivano da occorrenze significative che vengono riversate sull’Activity stesso. Dal punto di vista di un RA, un’Activity è una sequenza di eventi relativi alla stessa sessione di servizio, ad esempio un’Activity per il SipRA è la chiamata.
Un’Activity esiste nel dominio del Resource Adaptor, ciò significa che è compito di chi sviluppa l’RA a sviluppare Activity e ActivityInterface. Una volta istanziato, l’Activity prende il nome di Activity Object.
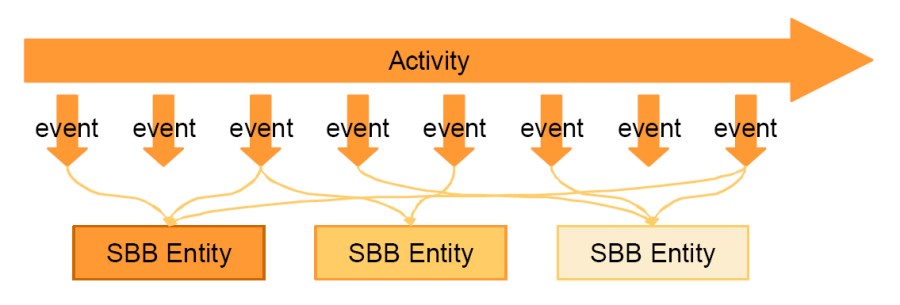
— Flusso degli eventi nell'Activity
Mentre lato RA troviamo Activity e Activity Interface, lo sviluppatore del servizio ha il compito di implementare Activity Context e Activity Context Interface, che astraggono le rispettive interfacce del Resource Adaptor e permettono una vista personalizzata per l’SBB dell’Activity sottostante.
L’Activity Context (AC) inoltre si può vedere come un canale in cui gli eventi possono transitare, infatti è possibile lanciare un evento su un AC, ed un SBB è in grado di ricevere eventi solo se è agganciato all’Activity Context che l’ha generato.
L’Activity Context rappresenta anche uno contenitore per la memorizzazione dei dati che gli SBB vogliono condividere con altri SBB.
Gli SBB Entity sono rapportati con gli Activity Context attraverso una relazione molti-a-molti. Il termine usato in SLEE per indicare questa connessione è attached (attach/detach). Attraverso questa relazione gli eventi possono transitare tra SBB e AC.
I casi che possiamo avere sono quindi:
-
Zero o più SBB sono attaccati a un Activity Context.
-
Ogni SBB può essere attaccato a zero o più Activity Context.
I motivi per cui vengono create queste relazioni possono essere:
-
L’SBB riceve un Initial Event. Lo SLEE collega questo SBB, che sarà un nuovo Root SBB Entity, all’Activity Context su cui l’Initial Event è lanciato.
-
SBB richiede esplicitamente l’attach ad un nuovo Activity Context che lui stesso ha creato e che è quindi in grado di riceverne gli eventi che vengono sul nuovo AC.
-
Un SBB può fare l’attach ad un Activity Context di un altro SBB. Questo permette di delegare in parte o tutta la gestione di eventi lanciati sull’AC ad un altro SBB.
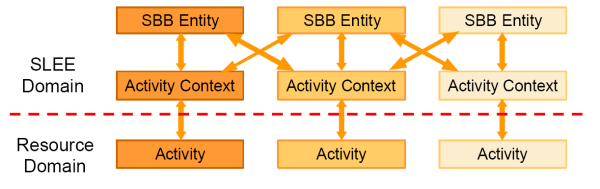
— "Relazione tra Activity Activity Context e SBB Entity"
Per la distruzione della relazione abbiamo i seguenti meccanismi:
-
Alla distruzione dell’Activity Context. lo SLEE esegue il detach di tutti gli SBB relazionati all’AC che viene distrutto.
-
Alla distruzione di un SBB. Lo SLEE prima di distruggere l’SBB, esegue il detach di tutti gli Activity Context a cui l’SBB era collegato.
-
Esplicitamente alla richiesta dell’SBB.
Da quanto detto finora possiamo fare un resoconto e osservale le relazioni interne a JAIN SLEE:
-
Activity Contexts 1 ←→1 Activity objects.
-
Activity Contexts 1 ←→ 0..∞ Activity Context Interface objects.
-
Activity Contexts 0.. ∞ ←→ 0..∞ SBB Entities.
-
Activity Contexts 0.. ∞ ←→ 0..∞ SLEE Facilities (queste relazioni vengono chiamare reference. Vedi 1.6.6).
Lo SLEE effettua il conteggio di delle relazioni tra SBB e i vari Activity Context. Il numero di relazioni che ha un SBB è il totale delle sue, sommata a tutte quelle che hanno i suoi figli. Questo conteggio è usato come il garbage collector di java per sapere quando un SBB, e tutto il suo albero sottostante, può essere rimosso (Figura 21).
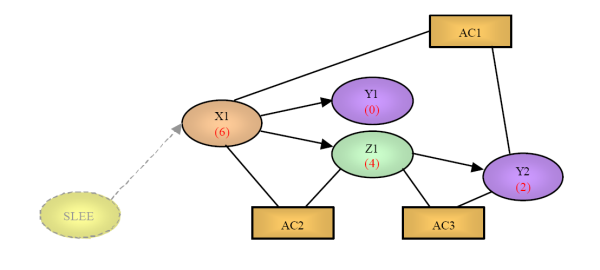
— Conteggio delle relazioni negli SBB Entity
Il ciclo di vita di un’Activity è composto da tre strati come mostrato in Figura 22.
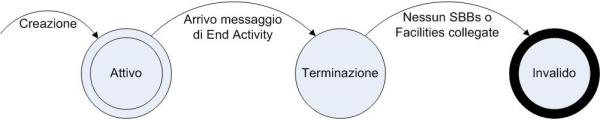
— Ciclo di vita dell'Activity Context
Alla creazione dell’AC, il suo stato è impostato come Attivo (Active). In questa condizione è in grado di gestire gli eventi scatenati su di esso da e per gli SBB, si possono agganciare SBBs o, come vedremo in 1.6.6, Facilities. Tutte le operazioni dell’AC sono permesse.
Quando l’Activity object sottostante l’AC passa nel suo stato di fine, anche l’Activity Context relativo passa nello stato di Terminazione (Ending). In questo stato l’unica operazione non ammessa è il lancio di eventi sull’AC stesso da parte di SBB. In questo stato l’AC continua ad erogare gli eventi in sospeso, poi lancia un Activity End Event ed alla fine effettua il detach di tutti gli SBBs e Facilities passando dunque allo stato Invalido (Invalid). Il questo stato l’AC è pronto per essere distrutto dallo SLEE.
Creazione dell’Activity
Un’Activity può essere creata da SLEE o da un’istanza di Resource Adaptor.
Nel primo caso abbiamo troviamo le seguenti Activity:
-
NullActivity – Rappresenta un’Activity non collegata ad una risorsa esterna. L’unico evento che SLEE è in grado di lanciare su di essa è l’ActivityEndEvent, mentre gli SBB potranno, come al solito, lanciare sulla NullActivity i loro eventi. È usata come canale di comunicazione tra SBB che vogliono collaborare attraverso un sistema di eventi privati, su cui è sempre possibile memorizzare attributi comuni. La rimozione di questo tipo di Activity, oltre a sfruttare il meccanismo del conteggio di attachment e reference, ed eventi restati, che è valido per tutte le Activity, può essere richiesta esplicitamente da un SBB correntemente collegato alla NullActivity. Per creare questo tipo di Activity viene usata la Factory NullActivityFactory e le NullActivity create avranno come owner lo SLEE. Questa Factory è usata anche nel caso in cui una sistema esterno si collega direttamente a SLEE per lanciare un evento, dato che non sfrutta un RA per lo scambio dei messaggi.
-
ServiceActivity – Lo SLEE lancia eventi riguardanti il ciclo di vita di un servizio su questa Activity. Ogni servizio in SLEE ha associata un’Activity di tipo ServiceActivity e su di essa vengono lanciati eventi di tipo Service Started Event. Un Root SBB di un servizio può stare in ascolto per questo evento nel caso in cui voglia intraprendere azioni all’avvio del servizio. Sulla ServiceActivity viene anche lanciato l’evento ActivityEndEvent quando un servizio viene arrestato dalla console di management di SLEE o quando SLEE stesso viene arrestato (in questo caso l’evento sarà lanciato su tutti i ServiceActivity esistenti).
-
ProfileTableActivity – Lo SLEE lancia eventi relativi alle Profile Table e al ciclo di vita del Profile sull’Activity chiama ProfileTableActivity. Ogni Profile Table ha associata un’Activity di questo tipo, il cui owner è sempre dello SLEE. Questo è in grado di lanciare eventi di tipo ProfileAddedEvent, ProfileUpdateEvent e ProfileRemovedEvent a seconda delle operazioni che coinvolgono la Profile Table sottostante. Gli SBB che sono interessati ai cambiamenti sulla Profile Table potranno usare il solito metodo di attachment all’Activity per essere notificati sulle operazioni che coinvolgono la Profile Table.
Per ciò che riguarda i Resource Adaptor Entity, questi sono in grado di creare Activity personalizzate in base al protocollo sottostante. Infatti la realizzazione di un Resource Adaptor prevede anche l’implementazione delle varie interfacce per l’Activity. Ad esempio, due Activity presenti nel Resource Adaptor Java Call Control sono JccConnection e JccCall.
Event, Event Type ed Event router
Un evento rappresenta un’occorrenza che avviene dentro o fuori SLEE. Sono usati per veicolare informazioni circa l’occorrenza tra le entità in SLEE. Un’entità in SLEE può essere lo SLEE stesso, un SBB, un Resource Adaptor o le SLEE Facilities. Sono anche usati per comunicare tra SBB in differenti SBB Entity Tree (vedi Figura 17).
Un evento è lanciato da una entità (produttore) e ricevuto da un’altra (consumatore). Lo SLEE ha il compito di instradare e recapitare l’evento al consumatore. Ogni evento è rappresentato in SLEE da un oggetto che lo implementa e da un tipo.
Il produttore di un evento, come detto prima, può essere:
-
Un Resource Adaptor: lancia eventi relativi alla risorsa che gestisce, chiamati resource events.
-
Lo SLEE: chiamati SLEE events, sono quelli relativi alla modifica dei profili e all’avvio/arresto di un servizio.
-
Facilities: solo lanciati dai moduli di utilità e vengono chiamati SLEE Facility events. Ogni utilità dichiara i propri relativamente alle funzioni che svolge.
-
SBB Entities: gli SBB in stato Attivo (vedi Figura 18) possono lanciare eventi personalizzati definiti dallo sviluppatore dell’SBB, detti Custom events.
Chi consuma un evento può essere invece solamente un SBB Entity. L’SBB dichiara il suo interesse alla ricezione di un evento attraverso il descrittore XML che lo accompagna e all’implementazione che lo sviluppatore fornisce per la gestione dell’evento stesso.
Il componente che gestisce un evento (produttore, consumatore e instradamento) ha la necessità di conosce delle informazioni circa il tipo di evento. Queste sono fornite dall’Event Type dell’evento (un file XML) che contiene dati per l’identificazione dello stesso: nome dell’evento, versione e il nome di chi lo ha realizzato (event-name, version, vendor).
Event Context
Ogni evento ha associato un suo Event Context. Questo permette la sospensione e la ripresa della consegna dell’evento al suo consumatore. Un evento che è stato sospeso non sarà consumato da nessun SBB fino alla sua ripresa, fornendo cosi a SLEE, ambiente asincrono, un modello comportamentale sincrono. Ad esempio, un SBB può sospendere la consegna degli eventi finché non gli arriva una risposta ad un messaggio asincrono inviato precedentemente.
Event routing
Il meccanismo di consegna degli eventi in SLEE si occupa delle seguenti funzioni:
-
Instanzia un nuovo Root SBB di un servizio per processare un evento.
-
Consegna gli eventi agli SBB Entity interessati tenendo conto della priorità delle relazioni padre-figlio.
L’arrivo di un evento può causare l’avvio di una nuova istanza di servizio in SLEE se l’evento è riconosciuto come initial event, quindi causa la creazione di un nuovo Root SBB. Quando un evento è lanciato da un produttore su un Activity Context la procedura usata da SLEE per determinare la creazione di una nuova istanza di servizio è la seguente:
-
Determina l’insieme dei servizi attivi che sono interessati alla ricezione di un evento iniziale dello stesso tipo di quello appena ricevuto.
-
Per ogni servizio selezionato:
-
Calcola il convergence name (vedi 1.6.5.3) del servizio, identificativo unico per le istanze di tutti i servizi presenti in SLEE. Se il servizio indica che l’evento da consegnare non è di tipo iniziale, basandosi sulle caratteristiche dichiarare dal Root SBB che l’evento iniziale deve rispettare, allora si procede analizzando il servizio successivo.
-
Altrimenti, si ricerca il Root SBB Entity del servizio con quel convergence name.
-
Se non viene trovato, si crea un nuovo Root SBB e si procede alla sua inizializzazione (sbbCreate e sbbPostCreate), all’assegnamento del convergence name e al suo attach con l’Activity Context su cui l’evento era stato lanciato.
-
Altrimenti, viene trovato il Root SBB e lo si attacca all’AC dell’evento appena lanciato.
-
-
Si richiama la gestione dell’evento sul Root SBB appena agganciato.
-
Se l’evento non è ti tipo iniziale, nell’Activity Context è già presente un riferimento agli SBB interessati all’evento e lo SLEE lo consegnerà seguendo la priorità delle relazioni padre-figlio esistenti se si presentano casi in cui deve instradare un evento da un padre a due o più figli.
Convergence name
Il Convergence name è una nome formato dalla concatenazione di alcune variabili del servizio in grado di identificare unicamente all’interno di SLEE un’istanza di servizio attiva. Le variabili prese in considerazione sono:
-
L’identificatore dell’Activity Context.
-
L’identificatore dell’Address Profile (vedi 1.6.7.1).
-
Address, l’indirizzo su cui è scattato l’utente, tipicamente un SipURI o TelURI.
-
L’evento e il tipo di evento.
-
Il Custom name, un nome fornito dal Root SBB per selezionare più nel dettaglio gli eventi che sono in grado di creare un nuovo servizio.
Concorrenza
La consegna degli eventi in SLEE fornisce dei controlli per una gestione corretta della concorrenza:
-
Lo SLEE garantisce che la stessa istanza di SBB non può essere eseguita da più thread. Questo significa che lo SLEE invocherà in maniera seriale tutti i metodi di un SBB Entity, inclusi quelli che gestiscono gli eventi, il ciclo di vita dell’SBB stesso e le chiamate locali sincrone.
-
Lo SLEE garantisce che due o più SBB Entity non possano ricevere in modo concorrente eventi su un singolo Activity Context.
-
Dato che gli eventi sono sempre lanciati su un Activity Context, lo SLEE richiamerà serialmente gli SBB Entity che possono ricevere l’evento in un ordine dipendente dalla loro priorità.
SLEE Facilities
Lo SLEE definisce un set di utilità chiamate Facility usabili sia da SBBs che da Resource Adaptor che Profile. Il loro compito è di fornire in funzioni per svolgere le funzioni più comuni. Sono:
-
Timer Facility – fornisce le funzionalità necessarie per effettuare azioni periodiche o ad una fissata scadenza, generalmente nell’ordine dei secondi o dei minuti.
-
Alarm Facility – è usata per il lancio o il rientro di allarmi. Attraverso questa Facility un componente dello SLEE può notificare ad un sistema esterno, attraverso MBean e JMX, la presenza di un errore. Il sistema client che attende queste notifiche può anche fornire a SLEE dei filtri per essere richiamato solo su eventi a cui è interessato.
-
Trace Facility – come il nome fa intendere, è l’utilità che gestisce i messaggi di log che ogni componente dello SLEE può generare. Fornisce un completo set di classi per poter ricevere il log via rete, via JMX, su console o su file in base al livello di dettaglio desiderato e al modulo (o moduli) desiderato.
-
Activity Context Naming Facility – fornisce un automatismo di denominazione globale degli Activity Contexts per il loro recupero attraverso una lookup JNDI.
-
Profile Facility – per la memorizzazione dei dati che un SBB ha necessità di memorizzare in maniera persistente, si veda 1.6.7.
-
Event Lookup Facility – è usata dai Resource Adaptor per ottenere delle informazioni circa gli eventi installati in SLEE e che l’RA può lanciare.
Profile, Profile Table e Profile Specification
I Profile contengono dati che, al contrario di quelli condivisi sull’Activity Context, non sono volatili. Queste informazioni andranno memorizzare in sistemi esterni allo SLEE, come databases, directory ldap o file, e attraverso le interfacce di Profile si potrà accedere a queste informazioni in maniera indipendente dalla locazione fisica su cui sono memorizzati.

— Rappresentazione dei Profiles
Le specifiche SLEE definiscono come creare i Profile Schema, che rappresentano i tipi di dati da memorizzare. Possiamo così avere delle Profile Table legate ad un Profile Schema che contengono zero o più Profili.
Un Profile Specification definisce le interfacce, le classi e i deployment descriptor necessari a definire uno schema e il modo di accesso ai profili conformi a questo stesso schema (Figura 23).
Address Profile Tables
Una Profile Table può essere associata ad un servizio e contenere informazioni relative agli indirizzi degli utenti che permettono allo SLEE (attraverso dei filtri sugli initial events) di stabilire con ulteriore precisione se creare un nuovo Root SBB o usarne uno già istanziato. Queste tabelle prendono il nome di Address Profile Tables e tipicamente contengono una riga per ogni utente registrato.
Resource Adaptors
Il Resource Adaptor (RA) fornisce a SLEE un’interfaccia standard per la gestione delle risorse, indipendentemente dalla loro natura. Queste possono essere di svariato tipo, un File System, un server SMS, un server di posta elettronica, e cosi via. Rappresentano in un certo senso quello che le Api JDBC sono per i databases.
Un esempio di Resource Adaptor è il SIP-RA, che converte i messaggi SIP in eventi che SLEE è in grado di comprendere e gestire ed attraverso lo stesso, SLEE può inviare, o rispondere con, messaggi SIP sulla rete.
Un Resource Adaptor è composto da:
-
Resource Adaptor Type, definisce il contratto con cui un SBB interagisce con la risorsa. Un ra-type è indipendente dall’implementazione reale del Resource Adaptor e questo consente la realizzazione di servizi che possono usare differenti implementazioni dello stesso Resource Adaptor Type. Per gli RA più importanti (come quello per SIP o per l’MRFC) questa interfaccia è definita da un’organizzazione che raggruppa i vari produttori di JAIN SLEE e di Resource Adaptor (organismi come lo SLEE export group).
-
Resource Adaptor, è l’implementazione del Resource Adaptor Type. Ve ne possono essere anche più di una per lo stesso ra-type in una installazione di SLEE. È compito dell’amministratore del sistema indicare a SLEE quale di queste implementazioni usare.
-
Resource Adaptor Entity, rappresenta un’istanza effettiva dell’RA, una per ogni sessione di comunicazione instaurata, e può essere configurata dall’SBB a cui è attaccato indipendentemente dalle altre istanze esistenti dello stesso RA. Ad esempio, un SIP-RA può avere tanti RA Entity per quanti sono i dialoghi SIP esistenti in SLEE.
-
SLEE Endpoint, è l’interfaccia usata dal Resource Adaptor per avviare Activities, lanciare eventi su questa e terminarla.
Il Resource Adaptor Type è identificato dall’ormai conosciuta tripletta nome, fornitore e versione. RA Type che hanno lo stesso identificatore vengono considerati compatibili e interscambiabili.
Un RA Type è formato da questi componenti:
-
Event Types, dove sono specificati gli eventi che questo RA è in grado di lanciare.
-
Activity Types, identifica l’Activity dell’RA attraverso le interfecce e/o classi Java implementate.
-
Activity Object End Conditions, descrive per ogni Activity quali sono le condizioni che portano alla fine dell’Activity stessa.
-
Activity Context Interface Factory, fornisce le necessarie classi per la creazione di un Activity Context (vedi 1.6.4)
Il Resource Adaptor quindi è l’implementazione di un Resource Adaptor Type. È il reale connettore tra la risorsa e SLEE, e si occupa della creazione e terminazione dell’Activity e del lancio degli eventi sulla stessa.
L’istanza dell’RA è il Resource Adaptor Entity. Il suo ciclo di vita (Figura 24) è molto simile a quello del servizio. Inizia dalla sua creazione, se avviene con successo, e al posizionamento nello stato di Inattivo (Inactive). In questo stato, l’RA aspetta solo di essere attivato, passando allo stato di Active, per svolgere le sue funzioni: creazione di Activity e lancio di eventi.
Un Resource Adaptor Entity può essere anche disattivato, è in questo momento che si posiziona sullo stato di Attesa terminazione (Stopping) in cui attende la distruzione di tutte le Activity create in precedenza. Una volta liberate le risorse si riposiziona nello stato di Inactive, pronto per essere riattivato o rimosso.

— Ciclo di vita di un Resource Adaptor Entity
È dunque evidente che grazie al meccanismo delle interfacce separate tra Resource Adaptor e Resource Adaptor Type, la creazione di nuovi servizi può avvenire senza che sia presente la reale implementazione del RA-type.
Service
Un servizio è la realizzazione e l’installazione in SLEE di un artefatto che viene incontro alle nostre esigenze. Questo è una composizione di SBBs, descrittori, interfacce e classi implementate.
Un servizio è descritto nel suo insieme da file che indica:
-
Un nome globale dei servizio (formato da nome-servizio, versione, produttore).
-
Un riferimento al Root SBB
-
Il valore di default della priorità degli eventi nel servizio, e sarà lo stesso valore che lo SLEE assegnerà alla relazione creata tra SLEE e Root SBB (Figura 21).
-
Un riferimento opzionale alla Address Profile Table, usata dallo SLEE per determinare quando un nuovo Root SBB del servizio deve essere creato.
Grazie ai descrittori è anche possibile fornire due servizi che si riferiscono allo stesso Root SBB, ma che hanno differenti eventi scatenanti, con differenti priorità e differenti Address Profile Tables.

— Ciclo di vita di un servizio
Il ciclo di vita di un servizio passa dallo stato Inattivo (Inactive), che si ha al termine di un installazione avvenuta con successo in SLEE, alla sua attivazione (Active), che indica allo SLEE la possibilità da parte del servizio di ricevere initial-events, al suo arresto. Un servizio che viene fermato passa nello stato di Attesa terminazione (Stopping) finché tutte le sue istanze di servizio terminano. Questa azione causa il lancio dell’evento Activity End Event sugli Activity Context attivi del servizio per notificare alle istanze del servizio la loro terminazione e consentire di liberare tutte le risorse precedentemente allocate.
Quando non esistono più istanze attive, il servizio passa nello stato di Inattivo.
Service Creation Environment (SCE)
La creazione di un servizio per SLEE comporta la scrittura di molteplici file, descrittori, classi, configurazioni, ed altro ancora, che descrivono il flusso del servizio che l’operatore intende implementare. Questo insieme di file devono inoltre essere sempre mantenuti sincronizzati tra di loro per non avere errori nel momento dell’installazione o, peggio, nell’esecuzione del servizio. Come se non bastasse, l’installazione del servizio prevede la sua pacchettizzazione in un formato ben definito per ogni tipo di modulo: Servizio, Resource Adaptor, Eventi, SBB…
Ritornando all’origine, l’aspetto a cui puntano le specifiche SLEE e tutta l’architettura Java JAIN è ridurre il Time-to-Marker di un servizio, dalla sua creazione alla sua installazione nel network. Si è reso quindi necessaria l’ideazione di un ambiente grafico per la modellazione e lo sviluppo/installazione dei nuovi servizi e per automatizzare le procedure di packaging dei componenti che li formano. Questo ambiente prende il nome di SCE – Service Creation Environment.
L’SCE è un workbench dove la realizzazione di un nuovo servizio avviene attraverso la composizione, in modalità grafica, di blocchi (che rappresentano i Service Building Block) e dei collegamenti tra di essi.
Un esempio è mostrato in Figura 26 dove viene realizzato un servizio SLEE nell’ambiente grafico SCE-SE, un prodotto di Alcatel-Lucent.
Molti degli ambienti SCE esistenti sono dei plug-in per il più famoso e importante IDE Java in circolazione, Eclipse. Grazie alla sua architettura e ai suoi tools grafici messi a disposizione gratuitamente (come GEF ed EMF), Eclipse rende semplice la creazione di ambienti SCE molto potenti e ricchi di funzionalità dato che la comunità che ruota attorno a questo IDE sforna centinaia di nuovi plug-in ogni anno. Inoltre, l’uso di questo IDE giova anche nella scrittura del codice Java per il servizio che stiamo andando a realizzare. Infatti, quando abbiamo necessità non contemplate tra i wizard grafici messi a disposizione dall’ambiente, o quando il servizio richiede delle funzionalità non comuni o personalizzate, è necessario manipolare il codice Java che l’ambiente crea dietro la vista del disegno. Dato che Eclipse è nato come ambiente di sviluppo per Java, abbiamo tutto il necessario per programmare confortati dalle ricche funzionalità che questo IDE mette a disposizione.
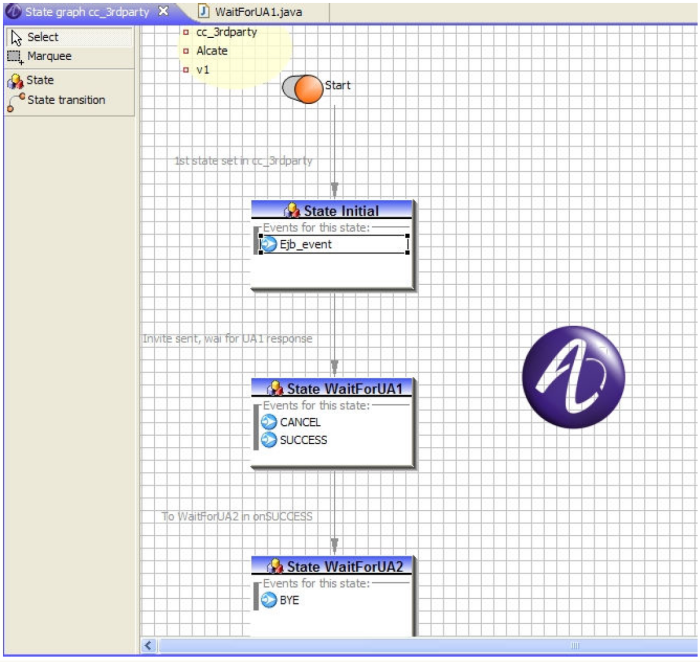
esempio di creazione di un servizio SLEE
— SCE-SE di Alcatel-Lucent
— SCE-SE di Alcatel-Lucent
Maggiori dettagli nel paragrafo 1.7.5, dove vedremo l’implementazione di SCE in Mobicents: EclipSLEE.

Mobicents
Mobicents è la prima e sola implementazione libera, open source e certificata delle specifiche JAIN SLEE. È un Application Server event-driver, altamente scalabile e fault-tolerance certificato sulle specifiche 1.0 di JAIN SLEE.
Red Hat ha acquisito Mobicents nel 2007 per completale la propria offerta di middleware anche in campo TLC. Infatti va così a creare la cosiddetta JBoss Communication Platform [8], un insieme di tecnologie per offrire servizi integrati di voce, video, data, instant messaging e presente, ma non solo.
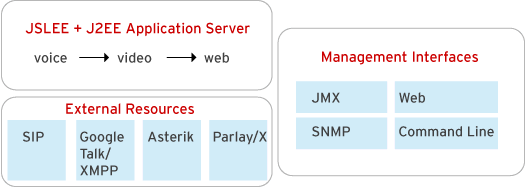
— JBoss Communication Platform
Oltre al mondo telecom, Mobicents è adatto in molte situazioni in cui il dominio architetturale è basato su eventi, grandi volumi di traffico e bassi ritardi. Esempi di questi ambienti possono essere l’ambito finanziario, il trading, l’online gaming o i sistemi distribuiti.
Il progetto Mobicents include codice proveniente dal NIST Advanced Networking Technologies Division ed è supportato da Portugal Telecom Innovacau, Telecom Italia, University of Genova, Vodafone R&D, T-Mobile, Lucent Technologies, Open Cloud, Aepona, NEC Japan, JBoss, Inc. ed altri.
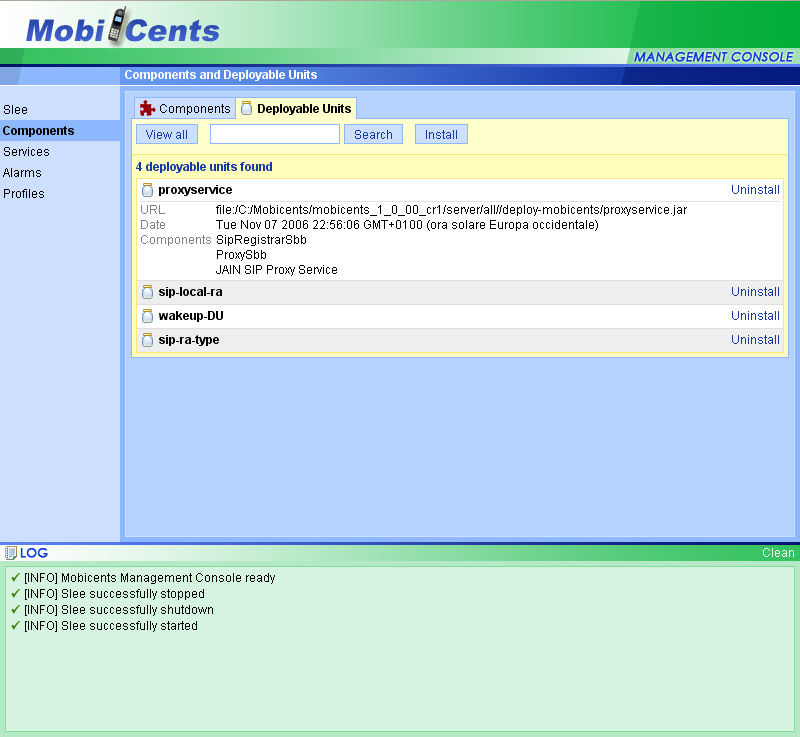
— Mobicents Management Console
Installazione
L’ultima versione disponibile di Mobicents al momento della stesura è la 1.2 Beta2. Questa release è distribuita insieme alla versione 4.2.2 GA di JBoss Application Server, su cui si basa. Sia Mobicents AS che JBoss AS sono sviluppati al 100% con Java. Questo permette di eseguire gli Application Server in ogni piattaforma in grado di far girare Java2 Standard Editino 1.5. L’installazione di Mobicents occupa circa 230 Mb di spazio su HD.
Mobicents, in quanto progetto open source, può essere reperito dalle pagine di SourceForge.net, dove è possibile scaricare sia il binario che i sorgenti.
La distribuzione di Mobicents contiene 4 cartelle:
-
server: il core di Mobicents
-
resource: i Resource Adaptor a corredo con la distribuzione
-
tools: utilità per la gestione del progetto e degli RA, contiene inoltre il CLI (Command Line Interface)
-
examples: sei progetti di esempio su alcune delle caratteristiche più interessanti di Mobicents.
Mobicents usa i seguenti componenti di JBoss:
-
JMX Microkernel per i servizi di IoC (Inversion of Control) e il management
-
JNDI
-
JTA per le transazioni
-
TreeCache per la replica dei dati nei sistemi ridondati
Mobicents non usa EJD e JMS per la propria architettura. Gli SBB e il routing degli eventi è stato implementato da zero per migliorare le prestazioni dallo JSLEE Expert Group.
Avvio di Mobicents
Per avviare Mobicents basta semplicemente posizionarsi con la linea di comando nella cartella server, settare la variabile d’ambiente JBOSS_HOME facendola puntare alla directory server della distribuzione di Mobicents e digitare bin/run.sh:
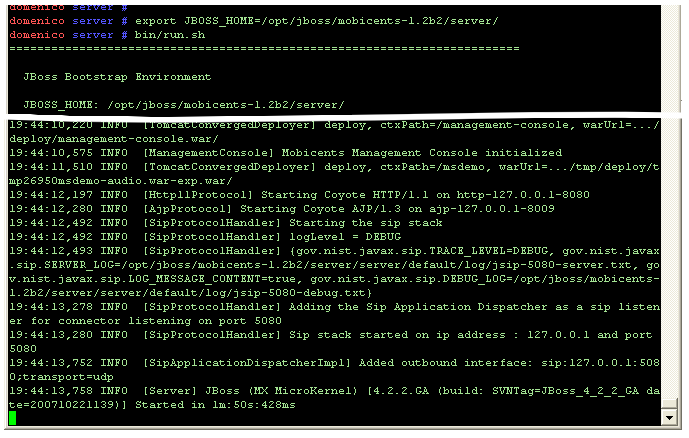
— Console di Mobicents appena avviato
Mobicents Management Console
Mobicents viene distribuito insieme alla Web Application MMC che abilita la gestione del server SLEE e il deploy di servizi, Resource Adaptor e profili direttamente da web.
La webapp è raggiungibile all’indirizzo http://localhost:8080/management-console/ dalla stessa macchina su cui già Mobicents. Il server, di default, ascolta sull’interfaccia di look back, 127.0.0.1, quindi se non viene modificato il parametro di avvio di JBoss la console non è raggiungibile dalle altre macchine. (Figura 28 e Figura 30).
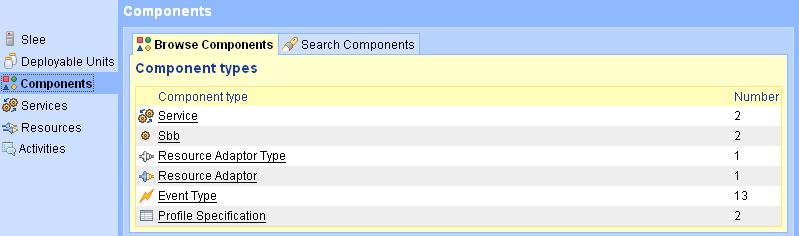
— MMC - Vista componenti
Tramite la Management Console è possibile esplorare tutte le entità installate con i loro riferimenti e i percorsi di installazione, gli Activity Contexts con il loro tempo di vita, i componenti che sono installati suddivisi per categoria, i servizi e molto altro. È anche possibile arrestare ed avviate servizi, resource adaptor, profili e l’intero SLEE.
Installazione dei Resource Adaptor e dei Servizi di esempio
Mobicents è fornito con diversi Resource Adaptor, tra i quali:
-
SIP RA – abilità all’uso delle API JAIN SIP e le estende con funzionalità di SIP Registrar e Proxy Service.
-
XMPP/GTalk RA – permette interfacciamento a server e client XMPP attraverso l’uso delle librerie Smack.
-
Asterisk RA – crea un link tra Mobicents e il PBX software open source più popolare.
-
Diameter RA – questo RA permette lo scambio di messaggi diameter per i protocolli Ro, Rf e Sh descritti in 1.4.6.4
-
SMPP RA – abilita la connessione ad un server SMSC per lo scambio si messaggi SMS
-
HTTP Client RA – rappresenta il componente che esegue richieste HTTP
-
HTTP Server RA – componente che risponde alle richieste HTTP
L’installazione può avvenire secondo tre modalità:
-
Attraverso la MMC – dalla console è possibile richiamare una pagina per il deploy di componenti a caldo. Basta selezionare il componente (deployment unit) e fare l’upload, sotto nella sezione di log apparirà il risultato dell’operazione.
-
Copiando i package delle installazioni direttamente sotto la directory di deploy di Mobicents. È una directory che, similmente per come avviene per JBoss, è controllata ciclicamente nell’attesa di un cambiamento al file system. All’aggiunta di una nuovo deployment unit si procede con l’installazione
-
Attraverso un task ant o maven rispettivamente per la versione 1.0 o 1.2 di Mobicents.
Per le modalità di installazione relativamente ad un determinato deploy esiste in genere un file di testo che documenta le modalità di installazione.
EclipSLEE – l’SCE di Mobicents
EclipSLEE è il plug-in per l’IDE Eclipse che facilita il lavoro con Mobicents e JAIN SLEE. In particolare, EclipSLEE è destinato ad aiutare la creazione di:
-
Profile Specification
-
Eventi
-
Service Building Blocks (SBB)
-
Service XML Descriptors
-
Deployable Units
EclipSLEE è facilmente installabile attraverso le funzionalità di aggiornamento automatico di Eclipse.

Parte Terza: Lo sviluppo sulla piattaforma JSLEE/Mobicents, SchedulingRA e sue applicazioni
La sezione descrivere dettagliatamente le scelte progettuali e la realizzazione del modulo che permette la calendarizzazione degli eventi in Mobicents.
Scheduling Resource Adaptor
Tra tutti i Resource Adaptor disponibili in ambiente open source per SLEE e Mobicents si sentiva la mancanza di uno che permettesse la pianificazione di azioni o servizi su base temporale.
Lo scopo dello Scheduling Resource Adaptor è quindi l’erogazione di eventi/servizi in un determinato momento. Esso è in grado di generare e lanciare dentro lo SLEE eventi di ogni tipo che sono stati precedentemente configurati.
Con lo Scheduling RA è possibile lanciare eventi:
-
Ad un momento ben preciso, una ed una sola volta.
-
Con cadenza giornaliera/settimanale/mensile/annuale.
-
In alcuni giorni definiti in un determinato calendario come, ad esempio, solo nei giorni festivi.
-
Ripeterli per un numero specifico di volte.
-
Ripeterli fino ad un’altra data/ora futura.
-
Ripeterli indefinitamente con un certo intervallo.
-
Una combinazione dei punti precedenti
Rapporto tra Timer Facility e Scheduling RA
Le specifiche JAIN SLEE descrivono, come abbiamo visto in 1.6.6, una facility di nome Timer. Anche se il nome può portare a pensare che la Timer Facility sia qualcosa di simile allo Scheduling RA, le differenze sono significative.
Lo Scheduling RA è pensato per lanciare eventi in determinati orari/giorni e dà la possibilità di memorizzare queste configurazioni su database (o su file) per non perderli al reboot del server o in caso di crash.
La Timer Facility è un’utilità che deve essere usata per richiamare eventi ad una scadenza molto vicina nel tempo (secondi o minuti al massimo). Anche se le specifiche JAIN SLEE V1.0 prevedevano la possibilità di memorizzazione di questi timer anche dopo un restart/crash del server SLEE, la versione successiva delle specifiche deprecava questo comportamento perché portava ad un uso scorretto della Facility.
Timer Facility, infatti, è particolarmente indicata per gestire i timeout che ci sono sui vari protocolli che gli RA supportano, come ad esempio i vari timeout presenti nel protocollo SIP (es. timer A, B, C vedi RFC 3261) o per iniziare un’azione e controllarne il risultato dopo un determinato lasso di tempo.
Implementazione
Oggi sono disponibili molti sistemi che permettono di pianificare azioni. In Windows abbiamo operazioni pianificate, in ambienti Linux né esistono molti (cron, anacron, vixie-cron solo per citarne alcuni) e praticamente ogni sistema operativo ne ha uno suo predefinito.
Nel mondo Java si trovano molti progetti il cui scopo è quello di eseguire azioni allo scadere di un preciso istante di tempo, ed alcuni di essi si basano proprio sul motore di scheduling del sistema operativo sottostante. La nostra scelta, invece, è ricaduta su un progetto molto importante, che non basa il suo sistema di funzionamento sul operativo e permette quindi una grande flessibilità e portabilità in ambienti diversi. Si tratta di Quartz [11], progetto open source della Open Symphony.
La scelta, per chi conosce il mondo Java, è risultata abbastanza ovvia. Quartz è lo scheduler Java più diffuso, flessibile e testato, ed offre molte funzionalità per l’aggancio ad Application Server J2EE, come la possibilità di partecipare a transazioni distribuite (XA) o locali (JTA), la capacità di effettuare il load-balance delle richieste e il supporto al fail-over configurato in modalità cluster. Se questo non bastasse, è importante sottolineare che è lo scheduler che viene usato e distribuito in bundle con JBoss 4 e superiori, piattaforma su cui poggia Mobicents.
Naturalmente negli impianti degli operatori TLC esistono già sistemi che permettono la pianificazione di azioni sulle proprie reti. Il codice del presente Resource Adaptor va incontro a questa problematica, ed il concetto di portabilità è stato tenuto bene in mente durante il suo sviluppo per facilitare il riuso del codice adattandolo ad un motore di scheduling diverso.
In JBoss 4.2 è presente il connettore JCA (J2EE Connector Architecture [14]) per Quartz, rappresentato dal quartz-ra.rar. Il connettore sposa le specifiche JCA 1.5 e rappresenta per JBoss quello che per Jain SLEE è un Resource Adaptor.
Grazie alla Java Connector Architecture, JBoss è in grado di gestire il ciclo di vita del sistema di scheduling al pari di una risorsa esterna, e tutte le applicazioni installate nell’AS possono condividere l’uso dello scheduler creato all’avvio del connettore. Questo avviene anche nel per quello che riguarda il nostro Scheduling RA.
Il Resource Adaptor di Quartz per J2EE fornito con JBoss permette alle applicazione scritte per questa piattaforma di interfacciarsi con il sistema di scheduling che l’Application Server mette a disposizione. Anche se concettualmente indicano la stessa cosa, infatti entrambi adattano i messaggi di una risorsa in messaggi che un altro sistema è in grado di gestire, il Resource Adaptor J2EE e il Resource Adaptor JAIN SLEE abbracciano specifiche diverse. Il primo è uno standard nato dalla collaborazione di software house di Application Server J2EE (Sun, Oracle, Iona, TIBCO, SAP, IBM, BEA) che volevano trovare uno standard che connettere sistemi eterogenei ai loro frame work.
Il secondo invece è una parte integrante delle specifiche JAIN SLEE e il compito fondamentale è quello di interfacciare un sistema esterno a SLEE attraverso eventi che SLEE stesso è in grado di gestire.
La presenza del Resource Adaptor di Quartz ha permesso l’installazione di un’applicazione web (quartz.war) che è in grado di gestire l’istanza di Quartz e le operazioni pianificate in esso contenute (vedi Figura 31).
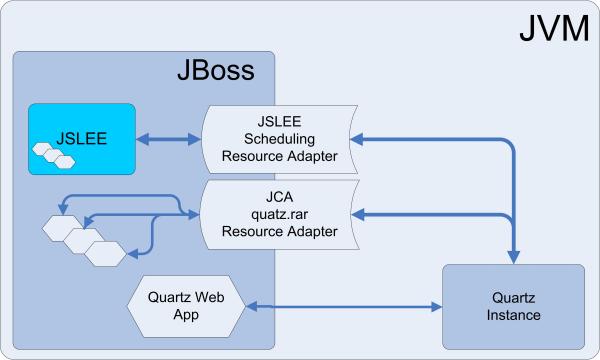
— Architettura dei JSLEE/JCA Resource Adaptor
Come funziona Quartz
Prima di parlare del Resource Adaptor, andiamo ad analizzare il funzionamento del software a cui ci interfacceremo, Quartz. Per sottoporre a Quartz un’attività è necessario creare una classe che implementi l’interfaccia org.quartz.Job. Questa dichiara un solo metodo, execute(JobExecutionContext context) che viene richiamato alla scadenza del timer. L’interfaccia e un esempio banale di classe che la implementa sono:
La classe appena presentata non fa altro che stampare un nuovo entry nel log, con le due famose parole “Hello World!” seguite dalla data corrente, ogni volta che ne è stata pianificata l’esecuzione.
Al metodo viene passato un JobExecutionContext che fornisce alcune informazioni al job relativamente al suo ambiente di esecuzione, come lo scheduler che lo ha eseguito, chi lo ha pianificato, dei parametri aggiuntivi forniti al momento della pianificazione e pochi altri dati.
Per pianificare l’esecuzione del Job vengono utilizzate classi che hanno il compito di specificare la modalità e le date di esecuzione del job stesso, sono i Trigger.
I Trigger vengono creati attraverso funzioni di utilità messe a disposizione da Quartz. Un esempio è questo che segue dove viene creato un Trigger che scatta ogni giorno alle 10:15:
Si possono realizzare Trigger ben più complessi come questo, che scatta ogni 30 secondi solo nel weekend (sabato e domenica):
o Trigger che scattano solo in determinati giorni, come le festività nazionali, o che vengono ripetuti indefinitamente ogni x secondi.
Quartz ha questi due concetti (di Job e di Trigger) che non tutti gli scheduler hanno. La differenziazione tra l’attività da eseguire e il quando eseguirla rende la pianificazione altamente flessibile, è infatti possibile creare un Job e associargli zero, uno o più Trigger.
Una volta creato il Job, e i relativi Trigger, non resta altro che schedulare la loro attività. Ogni istanza di Quartz contiene al suo interno uno o più scheduler. È quest’ultimo che gestisce e lancia le attività basandosi sui Trigger. Avere più scheduler a disposizione aiuta a tenere separata la loro gestione quando una stessa istanza di Quartz è usata da diversi attori all’interno dello stesso sistema. È possibile appunto gestire il ciclo di vita di uno scheduler separatamente dagli altri (fermato, avviato, in standby) e configurarlo separatamente. Si può ad esempio avere uno scheduler che memorizzi i Job/Trigger in un database e un altro no, o avere differenti parametri per il thread pool del’esecuzione dei Job. Per dare vita ad un nuovo scheduler basta richiamare la Factory che li crea, passando la configurazione che vogliamo assegnargli:
Al fine di sottoporre il Job allo scheduler è necessario introdurre un’altra classe: JobDetail. Questa non fa altro che arricchire il Job con un elenco di parametri ed alcune proprietà che indicano la tipologia del Job (volatile, duraturo o ripristinabile). Impostare un JobDetail come volatile significa che non verrà memorizzato nel database e sarà perso a fronte di un riavvio o di un crash dello scheduler o del sistema intero. Il flag duraturo indica che un JobDetail non sarà eliminato anche dopo che tutti i Trigger a lui associati siano stati scattati ed esauriti. Questo permette di rischedulare il Job con altri Trigger senza ridefinirlo. In fine, ripristinabile significa che se un Job era in esecuzione durante il crash o lo shutdown della macchina, e quindi non portato a termine, verrà messo in esecuzione al momento del restart di Quartz.
L’istanza di questa classe viene creata così:
e si può notare che le sole informazioni necessarie sono il nome che vogliamo dare al Job, la classe che implementa il Job stesso e i tre flag descritti appena sopra (rispettivamente volatile, duraturo e ripristinabile). Inoltre dà la possibilità di passare una serie di parametri al Job quando viene eseguito (attraverso il JobExecutionContext) riempiendo un’Hashmap con i dati necessari.
A questo punto basta richiamare il metodo scheduleJob dello scheduler e passargli l’istanza di una classe JobDetail appena creata con il Trigger per avviare il tutto:
Implementazione dello Scheduling Resource Adaptor Type
Il Resource Adaptor Type è quella parte dell’RA che stabilisce il contratto tra l’implementazione dell’RA e lo SLEE/SBB, e fornisce agli stessi il set di funzioni necessarie per pilotare la risorsa sottostante e gestirne il suo ciclo di , vedi 1.6.8.
Lo Scheduling Resource Adaptor Type realizzato contiene tutto il necessario per programmare l’RA sottostanze senza la necessità di avere l’implementazione reale dell’RA.
Al suo interno sono presenti le interfacce che estendono quelle delle specifiche:
-
SchedulingActivity
-
SchedulingActivityContextInterfaceFactory
-
SchedulingResourceAdaptorSbbInterface
La più rilevante è l’ultima, la SchedulingResourceAdaptorSbbInterface. Essa contiene la definizione dei metodi che un SBB può richiamare per gestire lo SchedulingRA. Essi Comprendono:
-
scheduleJob – sottopone a scheduling il Job e il Trigger passati in ingresso.
-
addTriggerToJob – Associano un nuovo Trigger ad un Job già prendere nello scheduler.
-
pauseJob / pauseTrigger – mettono in pausa rispettivamente un determinato Job o Trigger.
-
restartJob / restartTrigger – riprendono lo scheduling di un Job o di un Trigger.
-
deleteJob / deleteTrigger – rimuovono rispettivamente Job e Trigger.
-
triggerJob – esegue immediatamente un Job.
Le interfacce SchedulingActivity e SchedulingActivityContextInterfaceFactory rappresentano l’Activity su cui lavora il Resource Adaptor, vedi 1.6.4. L’Activity rappresenta un flusso di eventi che il Resource Adaptor è in grado di generare relativamente ad un sessione di dialogo con la risorsa sottostante. Nel nostro caso la risorsa è lo scheduler Quartz. Noi non abbiamo sessioni di dialogo, come può avvenire nel SipRA o nell’XMPPRA, ma dobbiamo scatenare solo un evento. Da qui si potrebbe pensare quindi ad un’Activity che possa lanciare solo quell’evento e l’Activity End Event. Ma nel nostro caso non è possibile, l’evento che andiamo a lanciare non dipende infatti dallo Scheduler Resource Adaptor ma è possibile lanciare un qualunque evento presente in SLEE. Da qui la scelta di implementare un’Activity che non è nient’altro che un NullActivity e lanciare l’evento in SLEE attraverso una connessione esterna. Dato ciò queste due interfacce potrebbero anche essere eliminate, ma vengono lasciate per un probabile futuro utilizzo:
Dato che il lavoro che compie il nostro Scheduler Resource Adaptor è quello di lanciare un evento in SLEE, l’RA-type contiene al suo interno l’unica implementazione necessaria dell’interfaccia Job di Quartz che si occupa appunto di lanciare questo evento in SLEE: la FireSleeEventJob.
Il metodo più rilevante di questa classe è execute(JobExecutionContext context) che allo scadere del timer viene richiamato dallo scheduler, eccolo (senza la parte di gestione delle eccezioni):
Dal codice si intravede il comportamento a fronte di un’esecuzione:
-
vengono recuperati i parametri con cui il Job è stato schedulato, JobDetail.
-
viene recuperata un’istanza di SleeConnectionFactory attraverso un lookup JNDI.
-
dalla factory si recupera una connessione allo SLEE
-
viene creato una nuova ExternalActivityHandle
-
si lancia l’evento sulla Activity appena creata.
Questi passi immettono in SLEE un nuovo evento con i parametri definiti al momento della schedulazione. E questo evento può ad esempio scatenare l’erogazione di un servizio.
I parametri contenuti nel JobDetail sono:
-
Event_Name, Event_Vendor, Event_Version – che identificano un preciso evento in SLEE (vedi 1.6.5).
-
Event_Parameter – è la classe concreta che rappresenta l’evento istanziata con i parametri di cui l’evento stesso necessita e serializzata in un array di byte.
Un esempio di classe evento è quella che useremo nella demo application per lanciare il delivery del servizio di informazione metrologiche su un account di GTalk:
Questo evento contiene il necessario per l’erogazione del servizio.
A volte è possibile, magari a seguito di una reinstallazione, riavvio o di un crash del sistema, che il server si trovi ad eseguire un Job storicizzato senza che sia installata, o disponibile nel classpath, la classe evento da cui è stato prodotta. Questo causerebbe un’eccezione durante il lancio del Job che potrebbe, in alcuni casi, dipendentemente dalla configurazione, all’arresto dello Scheduling RA. Per ovviare a questo problema si è deciso di serializzare la classe che implementa l’evento in un array di byte e gestire l’eccezione ClassNotFountException nella classe FireSleeJobEvent. Questo permette di gestire questi casi eccezionali senza pregiudicare il comportamento dello SchedulingRA in generale, e notifica la presenza di questa anomalia nel log.
L’RA-type si completa con una classe chiamata CustomObjectInputStream. È una classe di utilità che gestisce il loading della classe Java dall’array di byte.
In Java è possibile caricare dinamicamente una classe serializzata in più modi. Ma, come descrive Vladimir Roubtsov in [12], non è semplice capire come comportarsi a fronte di un problema di ClassLoading, anche perché la documentazione Java a riguardo è poco esaustiva. Il problema fondamentale è che una classe può essere caricata generalmente in due modi:
-
Class.forName(NomeDellaClasse)
-
Thread.currentThread().getContextClassLoader().loadClass(NomeDellaClasse)
Nel primo caso viene usato il ClassLoader che ha caricato la classe in cui è presente la chiamata, nel secondo viene usato quello relative al Thread che sta eseguendo la chiamata. Questa seconda modalità fu introdotta in Java2 per risolvere i problemi riscontrati dai framework che dovevano caricare dal loro interno classi implementate dall’utente. Ma la scarsa documentazione in merito porto molta confeziona al riguardo e già all’interno di Java2SE troviamo librerie che implementano l’una o l’altra senza armonizzare il tutto.
Per risolvere questo problema è stata realizzata per lo SchedulingRA Type la classe CustomObjectInputStream che estende la ObjectInputStream adottando una diversa strategia per il loading della classe evento:
Come si può notare, lo tattica seguita è quella di cercare di caricare la classe con il ClassLoader del contesto del Thread, ed in caso di fallimento si rigira la richiesta alla classe base ObjectInputStream che tenterà di caricare la classe con l’uso della chiamate Class.forName().
Per installare questo RA-type in SLEE è necessario corredarlo da un descrittore XML che definisce i nomi delle interfacce per Activity, Activity Context Interface Factory Interface e Resource Adaptor Interface:
Implementazione dello Scheduling Resource Adaptor
Nel package relativo all’RA è contenuto il codice che si connette a Quart per sottoporre i task da schedulare.
E composto da:
-
SchedulingResourceAdaptor – è il cuore dell’implementazione del Resource Adaptor e contiene il codice che istanzia un nuovo scheduler dall’istanza globale di Quartz. Il nuovo scheduler si chiama “SchedulingRAScheduler” e viene creato usando la configurazione del file quartz.properties presente nella directory net/homeip/dometec/mobicents/scheduling del jar contenente questo modulo. Per le proprietà di configurazione vedere il 1.8.6. questa classe implementa l’interfaccia ResourceAdaptor definita dalle specifiche JSLEE ed i metodi per l’iterazione con Quartz. Per il primo gruppo abbiamo:
-
getActivity / getActivityHandle / activityEnded / activityUnreferenced / queryLiveness – questi metodi sono richiamati da SLEE per conoscere lo stato delle Activity associate al Resource Adaptor. Devono essere implementati in modo da supportare sia chiamate concorrenti che chiamate rientranti [13]. Questi metodi non sono stati implementati in quando lo Scheduling Resource Adaptor non ha una sua Activity.
-
getSBBResourceAdaptorInterface – restituisce un’istanza della classe SchedulingResourceAdaptorSbbInterfaceImpl descritta appena sotto. L’unica istanza di questa classe viene creata dal metodo entityCreated.
-
getMarshaler – l’implementazione di questo metodo è necessaria per rendere disponibile a SLEE un meccanismo di serializzazione degli Event e delle Activity per distribuite gli oggetti tra diverse JVM (nel caso in sui SLEE giri su un cluster di nodi).
-
serviceInstalled / serviceActivated / serviceDeactivated / serviceUninstalled – questi sono dei metodi di callback che informano l’RA sul proprio ciclo di vita. L’implementazione di questi metodi è lasciata vuota in quanto lo Scheduling RA non necessita di effettuare particolari azioni a fronte dell’installazione o della rimozione dallo SLEE.
-
eventProcessingFailed / eventProcessingSuccessful – sono dei metodi che informano il Resource Adaptor sul corretto delivery degli eventi lanciati precedentemente. Per far scattare questo meccanismo è necessario lanciare un evento con i flags EventFlasg REQUEST_EVENT_PROCESSING_FAILED_CALLBACK e REQUEST_EVENT_PROCESSING_SUCCESSFIL_CALLBACK abilitati. Per lo Scheduler Resource Adaptor non sono stati implementati in quando questo RA non lancia eventi.
-
entityCreated / entityActivated / entityDeactivating / entityDeactivated / entityRemoved – sono i metodi che gestiscono il ciclo di vita del RA Entity. L’Entity (vedi 1.6.8 e Figura 24) è l’istanza concreta del Resource Adaptor. Lo Scheduling Resource Adaptor usa questi metodi per inizializzare il proprio scheduler “SchedulingRAScheduler” e creare l’istanza della classe che si interfaccerà con gli SBB. Alla creazione dell’Entity viene richiamata la entityCreated e si costruisce lo scheduler:
-
Lo scheduler viene instanziato con i parametri presenti nel file quartz.properties (1.8.6) e viene creata l’istanza di SchedulingResourceAdaptorSbbInterfaceImpl passando al costruttore l’RA stesso. Quando viene richiamato il metodo entityActivated, si aggancia l’RA all’albero JNDI del container, viene creata e agganciata sempre al JNDI la SchedulingActivityContextInterfaceFactoryImpl e viene avviato lo scheduler:
Vengono anche implementati i metodi entityDeactivated e entityRemoved. Il primo mette semplicemente in standby lo scheduler, il secondo lo arresta e deregistra il tutto dall’albero JNDI.
Per quello che riguarda i metodi relativi allo scheduling, vendono creati e implementati tutti i metodi necessari per gestire i Job e i relativi Trigger. Questi sono mappati uno a uno sull’interfaccia per l’SBB descritta appena sotto.
-
SchedulingResourceAdaptorSbbInterfaceImpl – implementa il contratto tra il Resource Adaptor e l’SBB (SchedulingResourceAdaptorSbbInterface) definito nell’RA-type. Contiene tutti i metodi che l’RA mette a disposizione per la gestione dei Job e dei Trigger così come sono descritti nel paragrafo precedente per l’interfaccia SchedulingResourceAdaptorSbbInterface.
-
SchedulingActivityImpl, SchedulingActivityHandle e SchedulingActivityContextInterfaceFactoryImpl – cosi come per l’RA-type, queste interfacce non vengono usate nel nostro Scheduling Resource Adaptor perché non gestisce Activity, ma vengono implementate solo nella loro forma base per un futuro cambio di strategia.
Il descrittore che segue accompagna l’RA, esso indica la classe che implementa il Resource Adaptor e la identifica con la solita tripletta Nome,Produttore,Versione:
Di seguito vengono presentati Sequence e Class Diagram per l’RA. Nel primo è visibile il processo di attivazione dello Scheduler che attraverso la classe FireSleeEventJob immette l’evento schedulato in SLEE.
Nel secondo è rappresentato l’avvio, l’attivazione, la disattivazione (messa in pausa dello scheduler) e l’arresto dello Scheduling Resource Adaptor Entity. Rappresenta quindi il ciclo di vita dell’RA.
L’ultimo disegno rappresenta il Class Diagram dell’RA e dell’RA-type con in evidenza le dipendenze da SLEE e da Quartz.
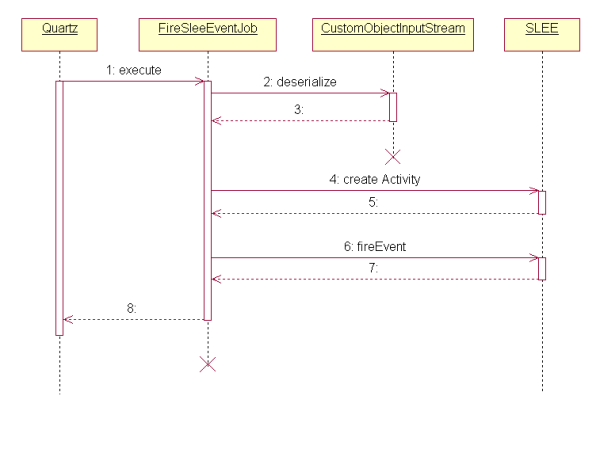
— Processo di attivazione dello scheduler
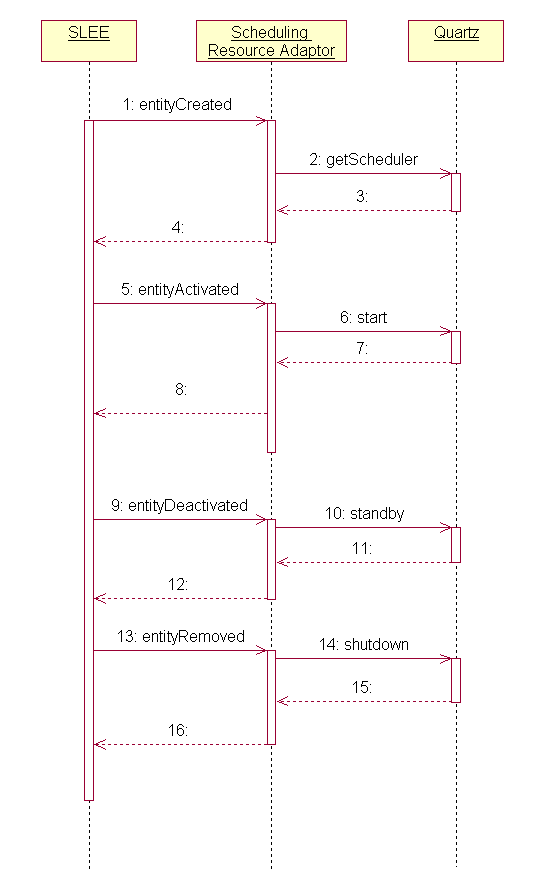
— Ciclo di vita dello Scheduling Resource Adaptor
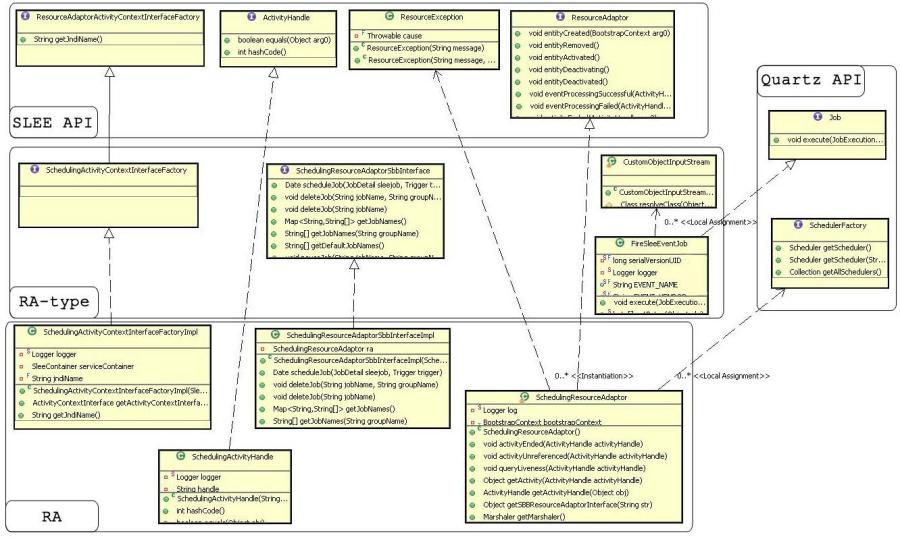
— Class Diagram di RA e RA-type con le dipendenze SLEE e Quartz in evidenza.
Packaging e Deployment
Tutti i Resource Adaptor, per essere installati in SLEE, devono essere rilasciati in formato JAR. Le specifiche SLEE descrivono dettagliatamente anche il processo di packaging che è necessario per fornire a SLEE dei file che è in grado di comprendere. Queste specifiche sono trasformate dal team di Mobicents in dei task Ant o Maven che, a fronte di una implementazione che usa directory standard, è in grado di creare dei Deployment Unit (questo è il termine usato nelle specifiche per indicare l’artefatto di Ant/Maven) perfettamente compatibili con SLEE.
La struttura del nostro progetto segue quella standard Mobicents per lo sviluppo con Maven, infatti, benché non usati, esiste una cartella events che potrebbe contenere gli eventi che il nostro Scheduling Resource Adaptor lancerebbe:
\scheduling\pom.xml
\scheduling\du\pom.xml
\scheduling\du\src\main\resources\META-INF\deploy-config.xml
\scheduling\events\pom.xml
\scheduling\events\src\main\resources\META-INF\event-jar.xml
\scheduling\ra\pom.xml
\scheduling\ra\src\main\java\net\homeip\dometec\mobicents\scheduling\SchedulingActivityContextInterfaceFactoryImpl.java
\scheduling\ra\src\main\java\net\homeip\dometec\mobicents\scheduling\SchedulingActivityHandle.java
\scheduling\ra\src\main\java\net\homeip\dometec\mobicents\scheduling\SchedulingActivityImpl.java
\scheduling\ra\src\main\java\net\homeip\dometec\mobicents\scheduling\SchedulingResourceAdaptor.java
\scheduling\ra\src\main\java\net\homeip\dometec\mobicents\scheduling\SchedulingResourceAdaptorSbbInterfaceImpl.java
\scheduling\ra\src\main\resources\META-INF\resource-adaptor-jar.xml
\scheduling\ra\src\main\resources\net\homeip\dometec\mobicents\scheduling\quartz.properties
\scheduling\ratype\pom.xml
\scheduling\ratype\src\main\java\net\homeip\dometec\mobicents\scheduling\CustomObjectInputStream.java
\scheduling\ratype\src\main\java\net\homeip\dometec\mobicents\scheduling\FireSleeEventJob.java
\scheduling\ratype\src\main\java\net\homeip\dometec\mobicents\scheduling\SchedulingActivity.java
\scheduling\ratype\src\main\java\net\homeip\dometec\mobicents\scheduling\SchedulingActivityContextInterfaceFactory.java
\scheduling\ratype\src\main\java\net\homeip\dometec\mobicents\scheduling\SchedulingResourceAdaptorSbbInterface.java
\scheduling\ratype\src\main\resources\META-INF\resource-adaptor-type-jar.xml
I files pom.xml sono l’input per Maven in cui sono descritte le procedure per creare il corretto packaging per i sorgenti e i compilati.
Alla fine del processo di compilazione viene prodotto l’artefatto di nome scheduling-ra-DU-1.2.0.GA-SNAPSHOT.jar. La versione 1.2 deriva semplicemente dal fatto che è stato realizzato per la versione 1.2 di Mobicents.
Il Deployment dell’RA avviene semplicemente copiando il file prodotto prima nella directory deploy del server o attraverso altre modalità (descritte in 1.7.4) similmente a come avviene per gli altri Resource Adaptor.
Uso
Attraverso lo Scheduling Resource Adaptor, uno sviluppatore SLEE è in grado di creare dei servizi che possono programmare il lancio di determinati eventi su base temporale. Ad esempio, si può impostare un determinato evento che si scatenerà una volta al giorno in un determinato orario, come avviene per le news che gli operatori inviano ai clienti via SMS.
Questi eventi sono rappresentati con la tipica tripletta usata in SLEE (nome-evento, nome-fornitore. versione) e sono lanciati dentro SLEE su un nuovo ExternalActivity.
Supponiamo che esista un servizio che esegua un ClickToCall, cioè un servizio che mette in comunicazione due utenti attraverso una chiama tradizionale attivata via web, e che molti siti già implementano. Questo in SLEE può essere realizzato tramite un BackToBackUserAgent come schematizzato in Figura 35.
— Simulazione servizio Click To Call
Il servizio viene erogato tramite una richiesta HTTP sull’http Server Resource Adaptor. Quest’ultimo trasforma la richiesta in un evento SLEE configurato come Initial Event sul Root SBB del servizio.
Se la nostra idea fosse quella di schedulare il servizio per farlo partire nel futuro è sufficiente usare il nostro Scheduler Resource Adaptor per fargli inviare un messaggio simile a quello che avrebbe generato l’HTTP Server Resource Adaptor nel momento desiderato. Il servizio demo che accompagna il progetto realizza una tecnica simile con l’evento StartVASHoroscopeServiceEvent:
quindi viene creato l’evento che ci interessa lanciare nel futuro, lo si inserisce in una Hash Map contenente anche la solita tripletta che identifica un evento e chiedere al nostro Scheduling RA di lanciarlo in futuro (il momento nel futuro è identificato dal Trigger che abbiamo visto in 1.8.2.1):
Dato che la richiesta di scheduling verrà fatta da un SBB, sopra si è richiamato l’uso del’interfaccia SchedulingResourceAdaptorSbbInterface, attraverso un lookup JNDI, per far giungere la richiesta al nostro scheduler.
Activity
La classe che viene eseguita alla scadenza prefissata non fa altro che creare un evento con i relativi parametri come descritto durante la creazione del timer, collegarsi con un’entità esterna a SLEE e lanciare questo evento sull’ExternelActivity appena creato, dato che l’evento non è collegato a nessun particolare Resource Adaptor. È stato deciso di utilizzare questo metodo perché i tipi di evento che l’RA lancerà non sono conosciuti a priori dall’RA stesso dato che sono configurabili a posteriori dagli sviluppatori di Servizi.
Configurazione
Lo Scheduler RA si poggia sul runtime di Quartz che viene fornito insieme a JBoss 4.2.2. La configurazione data prevede l’uso dell’istanza di Quartz attivata da JBoss, creando uno scheduler di nome “SchedulingRAScheduler”. Per modificare i parametri di avvio è sufficiente modificare il nome quartz.properties, nella directory "scheduling/ra/src/main/META-INF". La configurazione data è la seguente:
org.quartz.scheduler.instanceName = SchedulingRAScheduler
org.quartz.scheduler.instanceId = AUTO
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass =
org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.tablePrefix = qrtz_
org.quartz.jobStore.dataSource = QuartzDS
org.quartz.dataSource.QuartzDS.URL =
jdbc:mysql://192.168.1.51:3306/jobstore
org.quartz.dataSource.QuartzDS.driver = com.mysql.jdbc.Driver
org.quartz.dataSource.QuartzDS.user = root
org.quartz.dataSource.QuartzDS.password = mysql
org.quartz.dataSource.QuartzDS.maxConnections = 6
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 5
org.quartz.threadPool.threadPriority = 1
cosi configurato, il nuovo scheduler si poggiera per la persistenza dei propri task su un database MySQL (riga org.quartz.dataSource.QuartzDS.URL) seguita dai parametri di connessione al DB: utente/password e numero massimo di connessioni simultanee. Le restanti entry nel file di configurazione indicano la modalità in con cui i Job verranno scatenati. Viene indicato il numero di thread di cui dispone Quartz (org.quartz.threadPool.threadCount) e le rispettive priorità al momento della creazione. Infine notiamo le due classi che si occupano della memorizzazione dei Job (org.quartz.jobStore.class e org.quartz.jobStore.driverDelegateClass) che indicano appunto l’uso del database la prima e le modalità con cui accedervi la seconda.
Quartz Web Application
La QuartzWebApp è fornita sempre a corredo della distribuzione dello Scheduler RA. È una web application che permette di visionare di task e i trigger attualmente attivi per l’stanza selezionata di Quartz. È praticamente una versione leggermente modificata della webapp di Quartz (SVN http://svn.opensymphony.com/svn/quartz/tags/quartz_1-6-0/webapp) per permettere la sua esecuzione dentro il contesto di Mobicents. L’installazione avviene semplicemente compilando il progetto con ant e copiando l’artefatto creato sotto /dist nella directory di deploy del server JBoss (/deploy). L’utenza di default per il sito è quartz/quartz.
Di seguito alcuni screenshot dell’applicazione web:
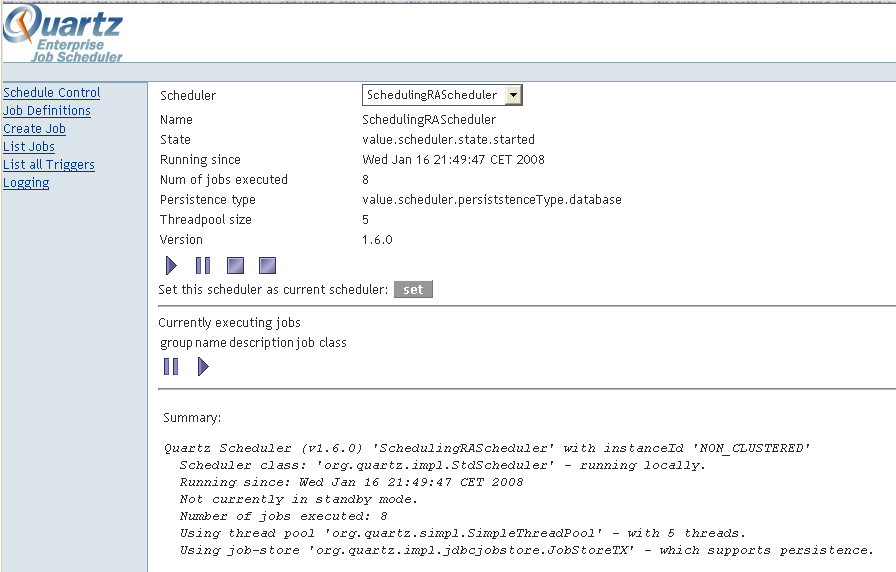
— Pagina principale che permette la gestione dello Scheduler
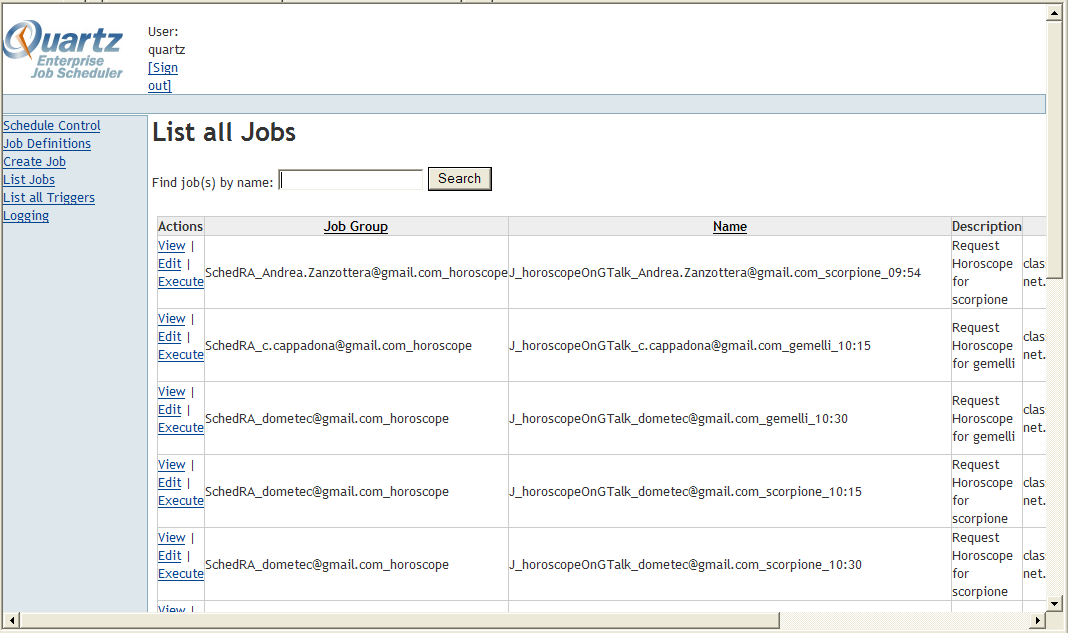
— Management dei singoli Job schedulati
Download e License
L’intero progetto dello Scheduling RA, corredato con degli esempi di servizio, è disponibile in [9].
Lo Scheduling Resource Adaptor è distribuito sotto la licenza GNU LGPL.
Quartz e la relativa web-app sono distribuiti sotto la licenza Apache 2.0 license.
Integrazione in Mobicents
Durante lo sviluppo del Resource Adaptor sono stati consultati, attraverso le pagine ufficiali del progetto e la mail-list del gruppo, i progettisti di Mobicents, i quali si sono avvicinati a quello che è lo Scheduler Resource Adaptor e stanno prendendo il considerazione il fatto di inserirlo nel rilascio ufficiale del progetto, con grande soddisfazione del suo creatore.
Un esempio reale: VAS-Services attraverso GTalk
Per mostrare le capacità del nuovo Scheduler Resource Adaptor è stata implementata un’applicazione di esempio che permette di ricevere giornalmente (o anche più spesso) informazioni meteorologiche o l’oroscopo del giorno.
Questa applicazione è composta da tre servizi SLEE (per un totale di cinque SBB):
-
VasServiceManager: è il servizio che si collega a GTalk attraverso l’utente [email protected] ed ha il compito di ricevere le richieste dell’utente e fornire le informazioni meteo o astrali. Qui viene usato lo SchedulingRA, esattamente quando un utente richiede la fornitura di un servizio su base oraria/giornaliera, o se desidera modificare/cancellare/testare un task già presente.
-
VasServiceExecutorWeather: allo scadere dell’ora prefissata, Quartz, attraverso lo SchedulerRA, invia a SLEE un evento di tipo initial con le informazione dell’utente. Se l’evento riguarda le informazioni meteorologiche, viene richiamato questo servizio che ha il compito di recuperare tali informazioni e mandarle all’utente attraverso il VasServiceManager.
-
VasServiceExecurotHoroscope: similmente al servizio descritto sopra, questo di occupa delle informazioni per l’oroscopo.
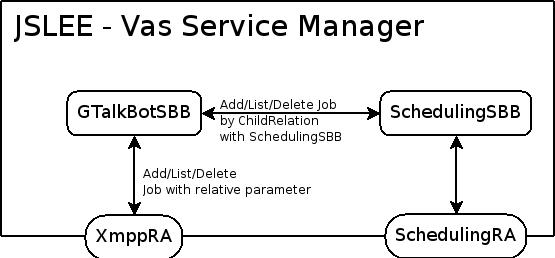
— Diagramma del servizio VasServiceManager
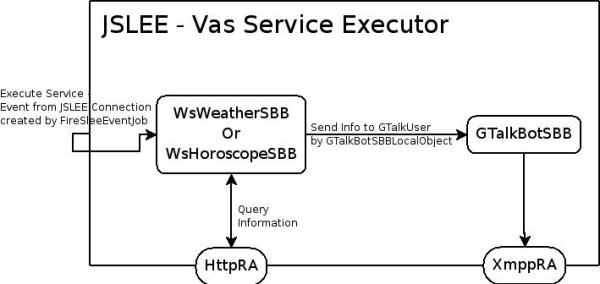
— Diagramma per i servizi Vas Service Executor
Nella realizzazione del servizio si è riscontrato un problema sull’XMPP Resource Adaptor: in caso di problemi di connettività, la disconnessione dal server Jabber di GTalk causava il lancio di un evento di tipo Activity End Event sull’Activity della connessione a GTalk, con la conseguente fine del servizio di Manager.
Il problema è stato affrontato attraverso la modifica del Resource Adaptor, introducendo, in caso di disconnessione causata da un errore della connessione, un timer per la riconnessione automatica ogni 30 secondi. La modifica è temporanea in quanto le API su cui si poggia l’XMPP-RA (Smack API) sono state aggiornate per supportare nativamente questa opzione ma l’RA usa ancora le librerie della versione precedente.
Installazione di Scheduling RA, WebApp e VAS-Services
I sorgenti di tutti i progetti sono disponibili nelle pagine del gruppo di discussione di Mobicents [9].
Per installare lo Scheduling RA basta seguire questi semplici passi (dalla macchina in cui è installato Mobicents e il sistema di build Maven [10]):
-
Decomprimere il file scheduling.zip in MOBICENTS_HOME/resources
-
da dentro la directory MOBICENTS_HOME/resources/scheduling digitare “mvn install” per richiamare la compilazione e l’installazione dell’RA.
L’installazione di esempio è ugualmente semplice:
-
Decomprimere il file vas-service.zip in MOBICENTS_HOME/examples
-
da dentro la directory MOBICENTS_HOME/ examples /vas-service digitare “mvn install” per richiamare la compilazione e l’installazione del servizio.
Per installare invece la Web Application per il controllo dello scheduler è sufficiente:
[1] Decomprimere il file webapp.zip in una directory a piacere
[2] digitare “ant” dalla directory appena creata per compilare ed eseguire il packaging del progetto.
[3] copiare l’artefatto che si trova nella cartella dist nella cartella deploy di JBoss
per vedere che l’installazione è andata a buon fine si può aprire il browser all’indirizzo http://localhost:8080/quartz e verificare la presenza della pagina di welcome dell’applicazione web.
Abbreviazioni ed Acronimi
- 3GPP
-
Third Generation Partnership Project
- 3GPP2
-
Third Generation Partnership Project 2
- 3PCC
-
3rd Party Call Control
- ACD
-
Automatic Call Distribution
- AIN
-
Advanced Intelligent Network
- ANSI
-
American National Standards Institute
- API
-
Application Programming Interface
- BGCF
-
Breakout Gateway Control Function
- CAMEL
-
Customized Applications for Mobile Networks Enhanced Logic
- CCF
-
Charging Collection Function
- CSCF
-
Call Session Control Function
- DHCP
-
Dynamic Host Configuration Protocol
- DNS
-
Domain Name Services
- ECF
-
Event Collection Function
- ENUM
-
Telephone Number Mapping
- ETSI
-
European Telecommunications Standards Institute
- HSS
-
Home Subscriber Server
- I-CSCF
-
Interrogating-CSCF
- IAD
-
Integrated Access Device
- IETF
-
Internet Engineering Task Force
- IFC
-
Initial Filter Criteria
- IM
-
Instant Messaging
- IMS
-
IP Multimedia Subsystem
- IM-SSF
-
IP Multimedia Service Switching Function
- INAP
-
Intelligent Network Application Protocol
- IP
-
Internet Protocol
- ISC
-
IMS Service Control
- ISDN
-
Integrated Services Digital Network
- ISG
-
Intelligent Services Gateway
- ISUP
-
ISDN User Part
- IVR
-
Interactive Voice Response
- J2EE
-
Java 2 Platform, Enterprise Edition
- JAIN
-
Java APIs for Advanced Intelligent Networks
- JCP
-
Java Community Process
- LNP
-
Local Number Portability
- MFRP
-
Multimedia Function Resource Processor
- MGCF
-
Media Gateway Control Function
- MGCP
-
Media Gateway Control Protocol
- MRF
-
Multimedia Resource Function
- MRFC
-
Multimedia Resource Function Controller
- MSFC
-
Media Server Function Control
- OSA
-
Open Services Access
- OSA-GW
-
Open Service Access – Gateway
- OSS/BSS
-
Operational and Business Support Systems
- P-CSCF
-
Proxy-CSCF
-
Policy Decision Function
- PoC
-
Push-to-Talk-over-Cellular
- PSTN
-
Public Switched Telephone Network
- PTT
-
Push-to-Talk
- QoS
-
Quality of Service
- RFC
-
Request For Comment
- RTP
-
Real-time Transport Protocol
- S-CSCF
-
Serving-CSCF
- SCF
-
Session Control Function
- SCIM
-
Service Capability Interaction Manager
- SCP
-
Service Control Point
- SCS
-
Service Capability Server
- SDHLR
-
Super Distributed Home Location Register
- SDP
-
Session Description Protocol
- SIP
-
Session Initiation Protocol
- SIMPLE
-
SIP for Instant Messaging and Presence Leveraging Extensions
- SLEE
-
Service Logic Execution Environment
- SS7
-
Signaling System No. 7
- SSP
-
Subscriber Services Profile
- TAS
-
Telephony Application Server
- TCAP
-
Transaction Capabilities Application Protocol
- TDM
-
Time Division Multiplexing
- THIG
-
Topology Hiding Internetwork Gateway
- TISPAN
-
Telecoms & Internet converged Services & Protocols for Advanced Networks
- UE
-
User Equipment
- UMTS
-
Universal Mobile Telecommunications System
- VoD
-
Video on Demand
- VoIP
-
Voice over Internet Protocol
- VPN
-
Virtual Private Network
- VXML
-
Voice Extensible Markup Language
- WCDMA
-
Wideband Code Division Multiple Access
- WLAN
-
Wireless Local Area Network
Bibliografia
Java in Telecommunications: Solutions for Next Generation Networks di Thomas C. Jepsen, Farooq Anjum ISBN 0471498262
Next Generation Network Services: Technologies and Strategies di Neill Wilkinson ISBN 0471486671
IMS, IP Multimedia Concepts and Services in the Mobile Domain Multimedia Concepts di Miikka Poikselka, Georg Mayer, Hisham Khartabil and Aki Niemi ISBN 047087113X
UMTS. Tecniche e architetture per le reti di comunicazioni mobili multimediali di Gennaro Columpsi, Marco Leonardi, Alessio Ricci ISBN 8820335913
Specifiche 3GPP
Tutte le Specifiche posso essere scaricate da http://www.3gpp.org/specs/numbering.htm. Di seguito la lista delle più rilevanti:
- TS 21.905
-
Vocabulary for 3GPP Specifications
- TS 22.066
-
Support of Mobile Number Portability (MNP); Stage 1
- TS 22.101
-
Service Aspects; Service Principles
- TS 22.141
-
Presence Service; Stage 1
- TS 22.228
-
Service requirements for the IP multimedia core network subsystem; Stage 1
- TS 22.250
-
IMS Group Management; Stage 1
- TS 22.340
-
IMS Messaging; Stage 1
- TS 22.800
-
IMS Subscription and access scenarios
- TS 23.002
-
Network Architecture
- TS 23.003
-
Numbering, Addressing and Identification
- TS 23.008
-
Organisation of Subscriber Data
- TS 23.107
-
Quality of Service (QoS) principles
- TS 23.125
-
Overall high level functionality and architecture impacts of flow based charging; Stage 2
- TS 23.141
-
Presence Service; Architecture and functional description; Stage 2
- TS 23.167
-
IMS emergency sessions
- TS 23.207
-
End-to-end QoS concept and architecture
- TS 23.218
-
IMS session handling; IM call model; Stage 2
- TS 23.221
-
Architectural Requirements
- TS 23.228
-
IMS stage 2
- TS 23.234
-
WLAN interworking
- TS 23.271
-
Location Services (LCS); Functional description; Stage 2
- TS 23.278
-
Customized Applications for Mobile network Enhanced Logic (CAMEL) - IMS interworking; Stage 2
- TS 23.864
-
Commonality and interoperability between IMS core networks
- TR 23.867
-
IMS emergency sessions
- TS 23.917
-
Dynamic policy control enhancements for end-to-end QoS, Feasibility study
- TS 23.979
-
3GPP enablers for Push-to-Talk over Cellular (PoC) services; Stage 2
- TR 23.981
-
Interworking aspects and migration scenarios for IPv4-based IMS implementations (early IMS)
- TS 24.141
-
Presence Service using the IMS Core Network subsystem; Stage 3
- TS 24.147
-
Conferencing using the IMS Core Network subsystem
- TS 24.228
-
Signalling flows for the IMS call control based on SIP and SDP; Stage 3
- TS 24.229
-
IMS call control protocol based on SIP and SDP; Stage 3
- TS 24.247
-
Messaging using the IMS Core Network subsystem; Stage 3
- TS 26.235
-
Packet switched conversational multimedia applications; Default codecs
- TS 26.236
-
Packet switched conversational multimedia applications; Transport protocols
- TS 29.162
-
Interworking between the IMS and IP networks
- TS 29.163
-
Interworking between the IMS and Circuit Switched (CS) networks
- TS 29.198
-
Open Service Architecture (OSA)
- TS 29.207
-
Policy control over Go interface
- TS 29.208
-
End-to-end QoS signalling flows
- TS 29.209
-
Policy control over Gq interface
- TS 29.228
-
IMS Cx and Dx interfaces : signalling flows and message contents
- TS 29.229
-
IMS Cx and Dx interfaces based on the Diameter protocol; Protocol details
- TS 29.278
-
CAMEL Application Part (CAP) specification for IMS
- TS 29.328
-
IMS Sh interface : signalling flows and message content
- TS 29.329
-
IMS Sh interface based on the Diameter protocol; Protocol details
- TS 29.962
-
Signalling interworking between the 3GPP SIP profile and non-3GPP SIP usage
- TS 31.103
-
Characteristics of the IMS Identity Module (ISIM) application
- TS 32.240
-
Telecommunication management; Charging management; Charging architecture and Principles
- TS 32.260
-
Telecommunication management; Charging management; IMS charging
- TS 32.299
-
Telecommunication management; Charging management; Diameter charging applications
- TS 32.421
-
Telecommunication management; Subscriber and equipment trace: Trace concepts and requirements
- TS 33.102
-
3G security; Security architecture
- TS 33.108
-
3G security; Handover interface for Lawful Interception (LI)
- TS 33.141
-
Presence service; security
- TS 33.203
-
3G security; Access security for IP-based services
- TS 33.210
-
3G security; Network Domain Security (NDS); IP network layer security
- TS 33.978
-
Security aspects of early IP Multimedia Subsystem (IMS)
Specifiche IETF
- RFC 2327
-
Session Description Protocol (SDP)
- RFC 2748
-
Common Open Policy Server protocol (COPS)
- RFC 2782
-
a DNS RR for specifying the location of services (SRV)
- RFC 2806
-
URLs for telephone calls (TEL)
- RFC 2915
-
the naming authority pointer DNS resource record (NAPTR)
- RFC 2916
-
E.164 number and DNS
- RFC 3087
-
Control of Service Context using SIP Request-URI
- RFC 3261
-
Session Initiation Protocol (SIP)
- RFC 3262
-
reliability of provisional responses (PRACK)
- RFC 3263
-
Session Initiation Protocol (SIP): Locating SIP Servers
- RFC 3264
-
an offer/answer model with the Session Description Protocol
- RFC 3265
-
SIP-Specific Event Notification
- RFC 3310
-
HTTP Digest Authentication using Authentication and Key Agreement (AKA)
- RFC 3311
-
The Session Initiation Protocol (SIP) UPDATE Method
- RFC 3312
-
integration of resource management and SIP
- RFC 3319
-
DHCPv6 options for SIP servers
- RFC 3320
-
Signalling Compression (SigComp)
- RFC 3323
-
a privacy mechanism for SIP
- RFC 3324
-
short term requirements for network asserted identity
- RFC 3325
-
private extensions to SIP for asserted identity within trusted networks
- RFC 3326
-
the reason header field
- RFC 3327
-
extension header field for registering non-adjacent contacts (path header)
- RFC 3329
-
security mechanism agreement
- RFC 3420
-
Internet Media Type message/sipfrag
- RFC 3428
-
SIP Extension for Instant Messaging
- RFC 3455
-
private header extensions to SIP for 3GPP
- RFC 3485
-
SIP and SDP static dictionary for signaling compression
- RFC 3515
-
the SIP REFER method
- RFC 3550
-
Real-time Transport Protocol (RTP)
- RFC 3574
-
Transition Scenarios for 3GPP Networks
- RFC 3588
-
DIAMETER base protocol
- RFC 3589
-
DIAMETER command codes for 3GPP release 5 (informational)
- RFC 3608
-
extension header field for service route discovery during registration
- RFC 3665
-
SIP Basic Call Flow Examples
- RFC 3680
-
SIP event package for registrations
- RFC 3725
-
best current practices for Third Party Call Control (3pcc) in SIP
- RFC 3824
-
using E164 numbers with SIP
- RFC 3840
-
indicating user Agent Capabilities in SIP
- RFC 3841
-
caller preferences for SIP
- RFC 3842
-
SIP event package for message waiting indication and summary
- RFC 3856
-
SIP event package for presence
- RFC 3857
-
SIP event template-package for watcher info
- RFC 3858
-
XML based format for watcher information
- RFC 3891
-
the SIP Replaces Header
- RFC 3903
-
SIP Extension for Event State Publication
- RFC 3911
-
the SIP Join Header
- RFC 4028
-
session timers in SIP
- RFC 4235
-
an INVITE-Initiated dialog event package for SIP
- RFC 4475
-
Session Initiation Protocol (SIP) Torture Test Messages
Ringraziamenti
Un grande grazie va a coloro i quali mi hanno dato sostegno in questi anni, che mi hanno sostenuto e rincuorato nei momenti più difficili e che hanno creduto nelle mie capacità. I miei genitori, Tita e Antonio, e mia sorella Annalisa.
Un ringraziamento speciale va al mio correlatore esterno, Antonio. Aver collaborato con lui in questi ultimi anni è stato di giorno in giorno sempre più proficuo. In tanti anni di lavoro non ho mai trovato una persona che, nonostante le grosse responsabilità e i momenti di lavoro duro, sia sempre stato così determinato, calmo e pronto ad ascoltare i suggerimenti di tutti.
Tanta stima e riconoscenza vanno al Professor Bettini, che mi ha seguito durante questi mesi di lavoro, e i cui consigli sono risultati utilissimi.
Ringrazio Gianluca, Maria ed Elena, amici e colleghi che mi hanno sostenuto ed aiutato durante la stesura della presente, e che grazie ai loro consigli posso vantare un lavoro, spero, privo di errori.
Come non citare Pietro e Sandro, amici che non si sono mai stancati di ricordarmi quanto fosse importante la laurea soprattutto nei momenti più bui e demoralizzanti del percorso formativo che ognuno incontra.
Infine un grande grazie a Cristina, la mia fidanzata e compagna di tanti momenti, per il suo importante sostegno.